Высокая доступность как сервис. Высокая доступность проектов. Что такое «пять девяток» и где их взять? Предоставление сервиса внешними поставщиками
Доступность
Основные понятия
Информационная система предоставляет своим пользователям определенный набор услуг (сервисов). Говорят, что обеспечен нужный уровень доступности этих сервисов, если следующие показатели находятся в заданных пределах:
- Эффективность услуг . Эффективность услуги определяется в терминах максимального времени обслуживания запроса, количества поддерживаемых пользователей и т.п. Требуется, чтобы эффективность не опускалась ниже заранее установленного порога.
- Время недоступности. Если эффективность информационной услуги не удовлетворяет наложенным ограничениям, услуга считается недоступной. Требуется, чтобы максимальная продолжительность периода недоступности и суммарное время недоступности за некоторой период (месяц, год) не превышали заранее заданных пределов.
В сущности, требуется, чтобы информационная система почти всегда работала с нужной эффективностью. Для некоторых критически важных систем (например, систем управления) время недоступности должно быть нулевым, без всяких "почти". В таком случае говорят о вероятности возникновения ситуации недоступности и требуют, чтобы эта вероятность не превышала заданной величины. Для решения данной задачи создавались и создаются специальные отказоустойчивые системы, стоимость которых, как правило, весьма высока.
К подавляющему большинству коммерческих систем предъявляются менее жесткие требования, однако современная деловая жизнь и здесь накладывает достаточно суровые ограничения, когда число обслуживаемых пользователей может измеряться тысячами, время ответа не должно превышать нескольких секунд, а время недоступности – нескольких часов в год.
Задачу обеспечения высокой доступности необходимо решать для современных конфигураций, построенных в технологии клиент/сервер. Это означает, что в защите нуждается вся цепочка – от пользователей (возможно, удаленных) до критически важных серверов (в том числе серверов безопасности).
Основные угрозы доступности были рассмотрены нами ранее.
В соответствии с ГОСТ 27.002, под отказом понимается событие, которое заключается в нарушении работоспособности изделия. В контексте данной работы изделие – это информационная система или ее компонент.
В простейшем случае можно считать, что отказы любого компонента составного изделия ведут к общему отказу, а распределение отказов во времени представляет собой простой пуассоновский поток событий. В таком случае вводят понятие интенсивности отказов и среднего времени наработки на отказ, которые связаны между собой соотношением
Рис. 13.1.
где i – номер компонента,
λ i – интенсивность отказов,
T i – среднее время наработки на отказ.
Интенсивности отказов независимых компонентов складываются:
Рис. 13.2.
а среднее время наработки на отказ для составного изделия задается соотношением
Рис. 13.3.
Уже эти простейшие выкладки показывают, что если существует компонент, интенсивность отказов которого много больше, чем у остальных, то именно он определяет среднее время наработки на отказ всей информационной системы. Это является теоретическим обоснованием принципа первоочередного укрепления самого слабого звена.
Пуассоновская модель позволяет обосновать еще одно очень важное положение, состоящее в том, что эмпирический подход к построению систем высокой доступности не может быть реализован за приемлемое время. При традиционном цикле тестирования/отладки программной системы по оптимистическим оценкам каждое исправление ошибки приводит к экспоненциальному убыванию (примерно на половину десятичного порядка) интенсивности отказов. Отсюда следует, что для того, чтобы на опыте убедиться в достижении необходимого уровня доступности, независимо от применяемой технологии тестирования и отладки, придется потратить время, практически равное среднему времени наработки на отказ. Например, для достижения среднего времени наработки на отказ 10 5 часов потребуется более 10 4,5 часов, что составляет более трех лет. Значит, нужны иные методы построения систем высокой доступности, методы, эффективность которых доказана аналитически или практически за более чем пятьдесят лет развития вычислительной техники и программирования.
Пуассоновская модель применима в тех случаях, когда информационная система содержит одиночные точки отказа, то есть компоненты, выход которых из строя ведет к отказу всей системы. Для исследования систем с резервированием применяется иной формализм.
В соответствии с постановкой задачи будем считать, что существует количественная мера эффективности предоставляемых изделием информационных услуг. В таком случае вводятся понятия показателей эффективности отдельных элементов и эффективности функционирования всей сложной системы.
В качестве меры доступности можно принять вероятность приемлемости эффективности услуг, предоставляемых информационной системой, на всем протяжении рассматриваемого отрезка времени. Чем большим запасом эффективности располагает система, тем выше ее доступность.
При наличии избыточности в конфигурации системы вероятность того, что в рассматриваемый промежуток времени эффективность информационных сервисов не опустится ниже допустимого предела, зависит не только от вероятности отказа компонентов, но и от времени, в течение которого они остаются неработоспособными, поскольку при этом суммарная эффективность падает, и каждый следующий отказ может стать фатальным. Чтобы максимально увеличить доступность системы, необходимо минимизировать время неработоспособности каждого компонента. Кроме того, следует учитывать, что, вообще говоря, ремонтные работы могут потребовать понижения эффективности или даже временного отключения работоспособных компонентов; такого рода влияние также необходимо минимизировать.
Есть разновидности бизнеса, где перерывы в предоставлении сервиса недопустимы. Например, если у сотового оператора из-за поломки сервера остановится биллинговая система, абоненты останутся без связи. От осознания возможных последствий этого события возникает резонное желание подстраховаться.
Мы расскажем какие есть способы защиты от сбоев серверов и какие архитектуры используют при внедрении VMmanager Cloud: продукта, который предназначен для создания кластера высокой доступности .
Предисловие
В области защиты от сбоев на кластерах терминология в Интернете различается от сайта к сайту. Для того чтобы избежать путаницы, мы обозначим термины и определения, которые будут использоваться в этой статье.- Отказоустойчивость (Fault Tolerance, FT) - способность системы к дальнейшей работе после выхода из строя какого-либо её элемента.
- Кластер - группа серверов (вычислительных единиц), объединенных каналами связи.
- Отказоустойчивый кластер (Fault Tolerant Cluster, FTC) - кластер, отказ сервера в котором не приводит к полной неработоспособности всего кластера. Задачи вышедшей из строя машины распределяются между одной или несколькими оставшимися нодами в автоматическом режиме.
- Непрерывная доступность (Continuous Availability, CA) - пользователь может в любой момент воспользоваться сервисом, перерывов в предоставлении не происходит. Сколько времени прошло с момента отказа узла не имеет значения.
- Высокая доступность (High Availability, HA) - в случае выхода из строя узла пользователь какое-то время не будет получать услугу, однако восстановление системы произойдёт автоматически; время простоя минимизируется.
- КНД - кластер непрерывной доступности, CA-кластер.
- КВД - кластер высокой доступности, HA-кластер.
На первый взгляд самый привлекательный вариант для бизнеса тот, когда в случае сбоя обслуживание пользователей не прерывается, то есть кластер непрерывной доступности. Без КНД никак не обойтись как минимум в задачах уже упомянутого биллинга абонентов и при автоматизации непрерывных производственных процессов. Однако наряду с положительными чертами такого подхода есть и “подводные камни”. О них следующий раздел статьи.
Continuous availability / непрерывная доступность
Бесперебойное обслуживание клиента возможно только в случае наличия в любой момент времени точной копии сервера (физического или виртуального), на котором запущен сервис. Если создавать копию уже после отказа оборудования, то на это потребуется время, а значит, будет перебой в предоставлении услуги. Кроме этого, после поломки невозможно будет получить содержимое оперативной памяти с проблемной машины, а значит находившаяся там информация будет потеряна.Для реализации CA существует два способа: аппаратный и программный. Расскажем о каждом из них чуть подробнее.
Аппаратный способ
представляет собой “раздвоенный” сервер: все компоненты дублированы, а вычисления выполняются одновременно и независимо. За синхронность отвечает узел, который в числе прочего сверяет результаты с половинок. В случае несоответствия выполняется поиск причины и попытка коррекции ошибки. Если ошибка не корректируется, то неисправный модуль отключается.
На Хабре недавно была на тему аппаратных CA-серверов. Описываемый в материале производитель гарантирует, что годовое время простоя не более 32 секунд. Так вот, для того чтобы добиться таких результатов, надо приобрести оборудование. Российский партнёр компании Stratus сообщил, что стоимость CA-сервера с двумя процессорами на каждый синхронизированный модуль составляет порядка $160 000 в зависимости от комплектации. Итого на кластер потребуется $1 600 000.
Программный способ.
На момент написания статьи самый популярный инструмент для развёртывания кластера непрерывной доступности - от VMware. Технология обеспечения Continuous Availability в этом продукте имеет название “Fault Tolerance”.
В отличие от аппаратного способа данный вариант имеет ограничения в использовании. Перечислим основные:
- На физическом хосте должен быть процессор:
- Intel архитектуры Sandy Bridge (или новее). Avoton не поддерживается.
- AMD Bulldozer (или новее).
- Машины, на которых используется Fault Tolerance, должны быть объединены в 10-гигабитную сеть с низкими задержками. Компания VMware настоятельно рекомендует выделенную сеть.
- Не более 4 виртуальных процессоров на ВМ.
- Не более 8 виртуальных процессоров на физический хост.
- Не более 4 виртуальных машин на физический хост.
- Невозможно использовать снэпшоты виртуальных машин.
- Невозможно использовать Storage vMotion.
Экспериментально установлено, что технология Fault Tolerance от VMware значительно “тормозит” виртуальную машину. В ходе исследования vmgu.ru после включения FT производительность ВМ при работе с базой данных упала на 47%.
Лицензирование vSphere привязано к физическим процессорам. Цена начинается с $1750 за лицензию + $550 за годовую подписку и техподдержку. Также для автоматизации управления кластером требуется приобрести VMware vCenter Server, который стоит от $8000. Поскольку для обеспечения непрерывной доступности используется схема 2N, для того чтобы работали 10 нод с виртуальными машинами, нужно дополнительно приобрести 10 дублирующих серверов и лицензии к ним. Итого стоимость программной части кластера составит 2 *(10 + 10)*(1750 + 550)+ 8000 =$100 000.
Мы не стали расписывать конкретные конфигурации нод: состав комплектующих в серверах всегда зависит от задач кластера. Сетевое оборудование описывать также смысла не имеет: во всех случаях набор будет одинаковым. Поэтому в данной статье мы решили считать только то, что точно будет различаться: стоимость лицензий.
Стоит упомянуть и о тех продуктах, разработка которых остановилась.
Есть Remus на базе Xen, бесплатное решение с открытым исходным кодом. Проект использует технологию микроснэпшотов. К сожалению, документация давно не обновлялась; например, установка описана для Ubuntu 12.10, поддержка которой прекращена в 2014 году. И как ни странно, даже Гугл не нашёл ни одной компании, применившей Remus в своей деятельности.
Предпринимались попытки доработки QEMU с целью добавить возможность создания continuous availability кластера. На момент написания статьи существует два таких проекта.
Первый - Kemari , продукт с открытым исходным кодом, которым руководит Yoshiaki Tamura. Предполагается использовать механизмы живой миграции QEMU. Однако тот факт, что последний коммит был сделан в феврале 2011 года говорит о том, что скорее всего разработка зашла в тупик и не возобновится.
Второй - Micro Checkpointing , основанный Michael Hines, тоже open source. К сожалению, уже год в репозитории нет никакой активности. Похоже, что ситуация сложилась аналогично проекту Kemari.
Таким образом, реализации continuous availability на базе виртуализации KVM в данный момент нет.
Итак, практика показывает, что несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений. Однако существуют ситуации, когда отказоустойчивость требуется, но нет жёстких требований к непрерывности сервиса. В таких случаях можно применить кластеры высокой доступности, КВД.
High availability / высокая доступность
В контексте КВД отказоустойчивость обеспечивается за счёт автоматического определения отказа оборудования и последующего запуска сервиса на исправном узле кластера.В КВД не выполняется синхронизация запущенных на нодах процессов и не всегда выполняется синхронизация локальных дисков машин. Стало быть, использующиеся узлами носители должны быть на отдельном независимом хранилище, например, на сетевом хранилище данных. Причина очевидна: в случае отказа ноды пропадёт связь с ней, а значит, не будет возможности получить доступ к информации на её накопителе. Естественно, что СХД тоже должно быть отказоустойчивым, иначе КВД не получится по определению.
Таким образом, кластер высокой доступности делится на два подкластера:
- Вычислительный. К нему относятся ноды, на которых непосредственно запущены виртуальные машины
- Кластер хранилища. Тут находятся диски, которые используются нодами вычислительного подкластера.
- Heartbeat версии 1.х в связке с DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- Openstack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Windows Server Failover Clustering в связке с серверной ролью “Hyper-V”;
- VMmanager Cloud.
VMmanager Cloud
Наше решение VMmanager Cloud использует виртуализацию QEMU-KVM. Мы сделали выбор в пользу этой технологии, поскольку она активно разрабатывается и поддерживается, а также позволяет установить любую операционную систему на виртуальную машину. В качестве инструмента для выявления отказов в кластере используется Corosync. Если выходит из строя один из серверов, VMmanager поочерёдно распределяет работавшие на нём виртуальные машины по оставшимся нодам.В упрощённой форме алгоритм такой:
- Происходит поиск узла кластера с наименьшим количеством виртуальных машин.
- Выполняется запрос хватает ли свободной оперативной памяти для размещения текущей ВМ в списке.
- Если памяти для распределяемой машины достаточно, то VMmanager отдаёт команду на создание виртуальной машины на этом узле.
- Если памяти не хватает, то выполняется поиск на серверах, которые несут на себе большее количество виртуальных машин.
Практика показывает, что лучше выделить одну или несколько нод под аварийные ситуации и не развёртывать на них ВМ в период штатной работы. Такой подход исключает ситуацию, когда на “живых” нодах в кластере не хватает ресурсов, чтобы разместить все виртуальные машины с “умершей”. В случае с одним запасным сервером схема резервирования носит название “N+1”.
VMmanager Cloud поддерживает следующие типы хранилищ: файловая система, LVM, Network LVM, iSCSI и Ceph . В контексте КВД используются последние три.
При использовании вечной лицензии стоимость программной части кластера из десяти “боевых” узлов и одного резервного составит €3520 или $3865 на сегодняшний день (лицензия стоит €320 за ноду независимо от количества процессоров на ней). В лицензию входит год бесплатных обновлений, а со второго года они будут предоставляться в рамках пакета обновлений стоимостью €880 в год за весь кластер.
Рассмотрим по каким схемам пользователи VMmanager Cloud реализовывали кластеры высокой доступности.
FirstByte
Компания FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально кластер работал под управлением OpenStack. Однако отсутствие доступных специалистов по этой системе (как по наличию так и по цене) побудило к поиску другого решения. К новому инструменту для управления КВД предъявлялись следующие требования:- Возможность предоставления виртуальных машин на KVM;
- Наличие интеграции с Ceph;
- Наличие интеграции с биллингом подходящим для предоставления имеющихся услуг;
- Доступная стоимость лицензий;
- Наличие поддержки производителя.
Отличительные черты кластера:
- Передача данных основана на технологии Ethernet и построена на оборудовании Cisco.
- За маршрутизацию отвечает Cisco ASR9001; в кластере используется порядка 50000 IPv6 адресов.
- Скорость линка между вычислительными нодами и коммутаторами 10 Гбит/с.
- Между коммутаторами и нодами хранилища скорость обмена данными 20 Гбит/с, используется агрегирование двух каналов по 10 Гбит/с.
- Между стойками с нодами хранилища есть отдельный 20-гигабитный линк, используемый для репликации.
- В узлах хранилища установлены SAS-диски в связке с SSD-накопителями.
- Тип хранилища - Ceph.

Данная конфигурация подходит для хостинга сайтов с высокой посещаемостью, для размещения игровых серверов и баз данных с нагрузкой от средней до высокой.
FirstVDS
Компания FirstVDS предоставляет услуги отказоустойчивого хостинга, запуск продукта состоялся в сентябре 2015 года.К использованию VMmanager Cloud компания пришла из следующих соображений:
- Большой опыт работы с продуктами ISPsystem.
- Наличие интеграции с BILLmanager по умолчанию.
- Отличное качество техподдержки продуктов.
- Поддержка Ceph.
- Передача данных основана на сети Infiniband со скоростью соединения 56 Гбит/с;
- Infiniband-сеть построена на оборудовании Mellanox;
- В узлах хранилища установлены SSD-носители;
- Используемый тип хранилища - Ceph.

В случае общего отказа Infiniband-сети связь между хранилищем дисков ВМ и вычислительными серверами выполняется через Ethernet-сеть, которая развёрнута на оборудовании Juniper. “Подхват” происходит автоматически.
Благодаря высокой скорости взаимодействия с хранилищем такой кластер подходит для размещения сайтов со сверхвысокой посещаемостью, видеохостинга с потоковым воспроизведением контента, а также для выполнения операций с большими объёмами данных.
Эпилог
Подведём итог статьи. Если каждая секунда простоя сервиса приносит значительные убытки - не обойтись без кластера непрерывной доступности.Однако если обстоятельства позволяют подождать 5 минут пока виртуальные машины разворачиваются на резервной ноде, можно взглянуть в сторону КВД. Это даст экономию в стоимости лицензий и оборудования.
Кроме этого не можем не напомнить, что единственное средство повышения отказоустойчивости - избыточность. Обеспечив резервирование серверов, не забудьте зарезервировать линии и оборудование передачи данных, каналы доступа в Интернет, электропитание. Всё что только можно зарезервировать - резервируйте. Такие меры исключают единую точку отказа, тонкое место, из-за неисправности в котором прекращает работать вся система. Приняв все вышеописанные меры, вы получите отказоустойчивый кластер, который действительно трудно вывести из строя. Добавить метки
Описанные выше метрики можно использовать при заключении соглашений о доступности сервиса с заказчиками. Эти договоренности входят составной частью в Соглашения об Уровне Сервиса. Приведенная ниже формула помогает определить, отвечает ли достигнутый Уровень Доступности согласованным требованиям:
Рис. 14.6. Формула доступности (источник: OGC)
Достигнутое время работоспособности системы равно разнице между согласованным временем работоспособности и случившемся временем простоя. Например: если была достигнута договоренность о 98% доступности сервиса в рабочие дни с 7.00 до 19.00 и в течение это периода был двухчасовой отказ сервиса, то достигнутое время работоспособности (процент доступности) будет равен:
(5x12- 2)/(5 х 12) х 100% = 96,7%
Анализ простоев системы (SOA)
Данный метод можно использовать для выяснения причин сбоев, изучения эффективности ИТ-организации и ее процессов, а также для представления и реализации предложений по усовершенствованию сервиса.
Характеристики метода SOA:
Широкая сфера действия: он не ограничивается инфраструктурой и охватывает также процессы, процедуры и аспекты корпоративной культуры;
Рассмотрение вопросов с точки зрения заказчика;
Совместная реализация метода представителями заказчика и ИТ-организации (команда метода SOA).
К числу преимуществ данного метода относятся эффективность подхода, прямая связь между заказчиком и поставщиком и более широкая область для предложений по улучшению сервиса.
Пост технического наблюдения (ТОР)
Данный метод заключается в наблюдении специальной командой ИТ-специалистов одного выбранного аспекта доступности. Его можно использовать в тех случаях, когда обычные средства не обеспечивают достаточной поддержки. Метод ТОР позволяет объединить знания проектировщиков и руководителей систем.
Расчеты доступности сервиса
Основным достоинством данного метода является рациональный, эффективный и неформальный подход, который быстро дает результат.
Программное обеспечение автоматизации процессов itil
- Bmc software
- Computer associates
- Hewlett-packard
- Microsoft
Bmc software
Компания BMC Software - всемирно известный разработчик и поставщик средств администрирования сетей, приложений, баз данных, ERP- и CRM-систем, повышающих доступность, производительность и восстанавливаемость критических бизнес-приложений и данных. Продукты BMC доступны для широкого спектра платформ, включая различные реализации и версии UNIX, Windows, OS/2, OS/390, OpenVMS и NetWare. Из характерных для продуктов BMC особенностей в первую очередь следует отметить ориентацию на поддержку соглашений об уровне обслуживания пользователей (Service Level Agreement, SLA) и построение модели функционирования, направленной на реализацию такого соглашения, а также их высокую производительность (рис. 1). Компания предлагает следующие семейства продуктов для управления ИТ-инфраструктурой:
- BMC Application Management - средство предназначено для управления производительностью и доступностью бизнес-приложений (включая приложения компаний Oracle и SAP) и серверных продуктов (таких, как Microsoft Exchange и J2EE-серверы BEA WebLogic, IBM WebSphere и др.);
- BMC Database Management - средство для администрирования, управления производительностью и восстановлением баз данных, управляемых СУБД ведущих производителей - Oracle, IBM, Microsoft, Sybase;
- BMC Infrastructure Management - средство для управления операционными системами серверов и мэйнфреймов, хранилищами данных, сетями, аппаратным обеспечением, ПО промежуточного звена, а также для оптимизации производительности указанных категорий программного обеспечения;
- BMC Operations Management - средство для выполнения рутинных операций по расписанию и для составления отчетов о событиях в сети;
- BMC Remedy Service Management - средство для поиска, обнаружения, моделирования сбоев в приложениях и реагирования на них;
- BMC Security Management - средство для управления правами доступа пользователей к приложениям и корпоративным ресурсам.
Данные приложений BMC могут храниться в базе данных о конфигурациях BMC Atrium CMDB (Configuration Management Database), обладающей удобными средствами визуализации данных.
Bmc software
Отметим, что продукты BMC включают документированный прикладной программный интерфейс, позволяющий создавать на их основе собственные решения и осуществлять интеграцию средств BMC с другими приложениями.

Рис. 1. Области управления ИТ-инфраструктурой, охватываемые продуктами BMC
Computer associates
Семейство продуктов Unicenter для управления ИТ-инфраструктурой компании Computer Associates (CA) можно адаптировать для применения практически в любой вычислительной среде.
В состав данного семейства входят следующие продукты:
- Unicenter Asset Management - инструмент для автоматизации управления ИТ-активами предприятия, с помощью которого осуществляется комплексный учет и контроль ИТ-ресурсов. Функциональность системы Unicenter Asset Management способствует повышению качества управленческих решений, связанных с ИТ-активами предприятия, и уменьшению сопутствующих рисков. Unicenter Asset Management обеспечивает мониторинг использования приложений на серверах, персональных компьютерах и других клиентских устройствах. Кроме того, этот продукт позволяет автоматизировать процессы управления ИТ-активами, включая учет и инвентаризацию программных и аппаратных средств, работающих в сети предприятия, обслуживание различных составляющих ИТ-инфраструктуры, администрирование лицензий и формирование отчетов в гетерогенных средах (рис. 2);

Рис. 2. Области интегрированного управления ИТ-инфраструктурой, охватываемые продуктами Computer Associates
- Unicenter Software Delivery - обеспечивает автоматизацию процессов развертывания и обновления программного обеспечения на настольных, мобильных и карманных компьютерах, а также на серверах в гетерогенных сетевых средах, включая доставку приложений, распространение исправлений и обновлений, управление системными конфигурациями и откат инсталляций на различных программных и аппаратных платформах. Данный продукт создает условия для повышения оперативности работы ИТ-служб и снижения расходов на информационную поддержку бизнеса за счет автоматизации ИТ-процессов и внедрения каталогов приложений с развитыми возможностями самообслуживания. Одним из ключевых преимуществ Unicenter Software Delivery является высокая степень автоматизации процессов установки и обслуживания ПО и гибкое и детальное управление разрешениями на доставку приложений;
- Unicenter Remote Control - это надежная и защищенная корпоративная система удаленного управления Windows-компьютерами. Перечень задач удаленного управления включает обслуживание удаленных сервисов, таких как сетевые приложения, администрирование серверов и удаленное управление компьютерами конечных пользователей (например, при оказании технической поддержки). Эта система является одним из лучших отраслевых решений в своем классе и обеспечивает централизованное обслуживание систем, управление на основе политик, разграничение прав доступа, аудит сеансов и развитые возможности администрирования. Unicenter Remote Control полностью отвечает запросам крупных предприятий в части удаленного управления и позволяет оператору одновременно выполнять сразу несколько задач: копировать файлы на удаленный компьютер, общаться с пользователем, запускать приложения, наблюдать и фиксировать пользовательские действия, а также управлять параметрами настройки и безопасности. Отметим, что при разработке Unicenter Remote Control особое внимание было уделено сокращению сроков внедрения и освоения системы.
Hewlett-packard
HP OpenView представляет собой комплекс программных продуктов, ориентированных на управление корпоративными информационными технологиями любого масштаба - от небольших систем на базе Windows-серверов до крупных распределенных систем на базе различных версий UNIX, Linux и Windows, содержащих несколько тысяч компьютеров. В данный комплекс входят средства управления сетями, операционными системами, приложениями, а также их производительностью, копированием и хранением данных, сервисами.
Портфель программных решений HP OpenView состоит из нескольких семейств продуктов (рис. 3), среди которых средства управления серверами и приложениями, хранением данных, сетями, Интернет-технологиями и телекоммуникационным оборудованием (существует спектр продуктов HP OpenView, предназначенный специально для телекоммуникационных компаний, и сегодня НР является наиболее известным поставщиком средств управления телекоммуникационным оборудованием). Отдельно отметим наличие в портфеле решений HP средств управления ИТ-услугами.

Рис. 3. Портфель программных решений HP OpenView для ИТ-подразделений
К средствам управления серверами и приложениями следует отнести в первую очередь HP OpenView Operations for Windows и HP OpenView Operations for Unix . Эти продукты предназначены для мониторинга и управления производительностью приложений, а также для осуществления контроля событий в сети и приложениях. HP OpenView Operations for Windows интегрируется со средствами управления сетевой инфраструктурой HP OpenView Network Node Manager , что позволяет производить автоматический поиск новых серверов, добавленных в сеть, а затем выполнять автоматическое развертывание требующихся компонентов и политик на основе результатов поиска сервисов.
Hewlett-packard
Для управления производительностью приложений в состав указанного семейства входят средства HP OpenView Performance Manager и Performance Agents , позволяющие с помощью единого интерфейса осуществлять централизованный мониторинг, анализ и прогнозирование использования ресурсов в распределенных и неоднородных средах, а также HP OpenView Performance Insight, помогающий осуществлять мониторинг событий в сети и приложениях, анализировать их. Решения HP OpenVew Report Packs и HP OpenView Reporter предназначены для создания отчетов о работе распределенной IT-инфраструктуры предприятия на основе данных, полученных от приложений HP OpenView.
Для управления идентификацией и доступом к ИТ-ресурсам в состав семейства HP OpenView входят продукты HP OpenView Select Identity, HP OpenView Select Access и HP OpenView Select Federation , а для управления резервным копированием и восстановлением данных серверных СУБД - HP OpenView Storage Data Protector . Последний из названных продуктов является решением корпоративного уровня для защиты данных и восстановления систем в чрезвычайных ситуациях, реализующим технологию мгновенного восстановления, а также альтернативные варианты аварийного восстановления для устранения внеплановых простоев, что позволяет восстановить работоспособность информационной системы за несколько минут.
Отметим также наличие в данном семействе продуктов, предназначенных для осуществления взаимодействия с конечными пользователями с целью улучшения качества их обслуживания, - HP OpenView Service Desk , а также средства мониторинга бизнес-процессов HP OpenView Business Process Insight и средства управления архитектурой, ориентированной на сервисы, - HP OpenView Service Oriented Architecture Manager .
Hewlett-packard
Для управления Интернет-сервисами в данном семействе продуктов предусмотрено решение HP OpenView Internet Services , позволяющее осуществлять внешнее зондирование прикладных служб, Интернет-сервисов и протоколов посредством моделирования запросов пользователей к каталогам, почтовым службам, веб-службам, сервисам удаленного доступа (в том числе коммутируемого и беспроводного доступа).
Семейство продуктов IBM Tivoli, предназначенных для управления приложениями предприятий различного масштаба, основано на наборе базовых компонентов, из которых строится решение для конкретного предприятия. Главной отличительной особенностью данного семейства продуктов является так называемое упреждающее управление IT-инфраструктурой, способное выявлять и устранять неисправности еще до их возникновения. Продукты семейства Tivoli доступны для платформ AIX, HP-UX, Sun Solaris, Windows, Novell NetWare, OS/2, AS/400, Linux, z/OS, OS/390. Отметим, что в последнее время IBM рекомендует внедрять продукты семейства Тivoli с целью следования методикам библиотеки ITIL (Information Technology Infrastructure Library), сместив акцент в позиционировании своих продуктов с управления ИТ-ресурсами и системами на управление ИТ-услугами (рис. 4).

Рис. 4. Некоторые из программных продуктов Tivoli, поддерживающих ITIL-процесс управления услугами
Семейство продуктов Tivoli включает решения для управления конфигурацией и операционной поддержки:
- IBM Tivoli Configuration Manager - позволяет управлять установкой и обновлением ПО, в том числе и на карманные компьютеры;
- IBM Tivoli License Manager - предназначено для инвентаризации программного обеспечения;
- IBM Tivoli Remote Control - позволяет устанавливать политики для управления IT-ресурсами предприятия и удаленно администрировать настольные системы;
- IBM Tivoli Workload Scheduler - дает возможность автоматизировать рабочие нагрузки.
Помимо средств управления конфигурациями, семейство продуктов Tivoli включает решения для управления производительностью и доступностью:
- IBM Tivoli Monitoring - для осуществления распределенного мониторинга различных систем, автоматического обнаружения и устранения проблем и анализа тенденций;
- IBM Tivoli Monitoring for Databases (поддерживаются СУБД производства IBM, Oracle и Microsoft) и Tivoli Manager for Sybase - для централизованного управления серверами и базами данных;
- IBM Tivoli Monitoring for Web Infrastructure - для управления web-серверами и серверами приложений;
- IBM Tivoli Monitoring for Applications - для управления бизнес-приложениями SAP;
- IBM Tivoli Analyzer для Lotus Domino 6.0 и IBM Tivoli Monitoring for Transaction Performance - для обнаружения проблем производительности систем, основанных на серверных продуктах самой IBM;
- IBM Tivoli Web Site Analyzer - для анализа трафика посетителей, статистики посещаемости страниц, целостности информационного наполнения web-сайта;
- IBM Tivoli Service Level Advisor - для обеспечения упреждающего управления и прогнозирования отказов посредством количественного анализа производительности;
- IBM Tivoli NetView - для управления сетью;
- IBM Tivoli Switch Analyzer - для обнаружения и заполнения всех коммутаторов сетевого уровня;
- IBM Tivoli Enterprise Console - для многоуровневого поиска причин неисправностей и анализа событий.
Кроме того, имеется ряд решений для автоматизированного управления распределением ИТ-ресурсов и пиковыми нагрузками.
В состав семейства Tivoli входят также продукты для обеспечения безопасности:
- IBMDirectory Server - для синхронизации данных о безопасности в масштабе всех используемых приложений;
- IBM Directory Integrator - для интеграции идентификационных параметров, содержащихся в каталогах, базах данных, системах коллективной работы и бизнес-приложениях;
- IBM Tivoli Identity Manager и IBM Tivoli Access Manager for Operating Systems - для управления доступом к приложениям и операционным системам;
- IBM Tivoli Risk Manager - для централизованного управления защитой сети.
Помимо этого семейство Tivoli включает широкий спектр продуктов для управления резервным копированием и системами хранения данных.
Microsoft
Хотя сегодня Microsoft и не является лидером рынка средств управления ИТ-инфраструктурой, средства управления приложениями производства этой компании применяются в нашей стране достаточно широко.
Основное назначение средств Microsoft Microsoft Systems Management Server (SMS) и Microsoft Operations Manager (MOM), а также средств администрирования, доступных пользователям последних версий серверных операционных систем Microsoft (таких, как Automated Deployment Services, Remote Installation Services, Microsoft Group Policy Management Console, Microsoft Windows Update Services), - управление программным обеспечением, автоматическая установка операционных систем Microsoft и предназначенных для них приложений, автоматическая доставка обновлений, управление доступом и правами пользвателей (рис. 5).

Рис. 5. Управление информационными системами с помощью Microsoft Operations Manager и Microsoft Systems Management Server
Microsoft Systems Management Server предназначен для обеспечения автоматического распространения и учета программного обеспечения в крупных распределенных системах на основе операционных систем самой Microsoft, включая планирование с определением оборудования и ПО в локальной сети, проверку, анализ, внедрение бизнес-приложений для различных целевых групп пользователей, установку приложений на вновь появившиеся рабочие места в соответствии с правами пользователя. Данный продукт позволяет осуществить целевую установку различного ПО для разных групп пользователей, а также решать проблемы, связанные с инвентаризацией ПО и с контролем над использованием ПО и аппаратных ресурсов за счет сбора информации об установленных в сети программных продуктах и оборудовании и об их использовании.
Microsoft
Microsoft Operations Manager предназначен для выявления и устранения неполадок в работе сети, оборудования и приложений за счет прямого мониторинга происходящих событий, а также состояния и производительности сетевых ресурсов и выдаче предупреждений о потенциальных проблемах (рис. 6).

Рис. 6. Мониторинг состония серверов с помощью Microsoft Operations Manager
Для управления ИТ-инфраструктурой небольших компаний или специализированными группами серверов (до 10 шт.) предназначен продукт Microsoft Operations Manager 2005 Workgroup Edition . Он позволяет выявить потенциальные опасности в функционировании программного обеспечения и благодаря встроенным средствам анализа предотвратить перерастание их в серьезные проблемы, повысить эффективность ИТ-операций, упростить поддержку гетерогенных платформ и приложений, а также создавать собственные пакеты обновления.
Кроме того, существуют отдельные решения для управления произвоительностью и для анализа событий для компонентов ИТ-инфраструктуры, основанной на серверных продуктах Microsoft, такие как Active Directory Management Pack - для отслеживания состояния службы каталогов Active Directory, Exchange Management Pack - для управления сервисами обмена сообщениями и хранилищами данных Exchange, а также ряд других продуктов. Для обеспечения взаимодействия со средствами управления ИТ-инфраструктурой производства других компаний имеется продукт MOM Connector Framework , позволяющий осуществлять двунаправленную трансляцию предупреждений и синхронизацию данных с помощью web-служб.
Управление иб
- Cobit - «цели контроля для информации и связанных с ней технологий»
- Читать раздел 1
- Читать раздел 1
- Читать раздел 1
- Читать раздел 1
Стандарт «Цели контроля для информации и связанных с ней технологий» (CobiT), сейчас уже в третьем издании, помогает реализовать многочисленные потребности в области управления, формируя взаимосвязи между бизнес-рисками, требованиями контроля и техническими вопросами. Это позволяет сформировать хорошую практику управления ИТ во всех группах процессов в рамках стандарта, также описать виды ИТ-деятельности в виде управляемой и логически выстроенной структуры. «Хорошая практика» по CobiT – это согласованные рекомендации экспертов, которые помогают оптимизировать инвестиции в информатизацию и предоставляют систему показателей, на которые можно ориентироваться в случае возникновения внештатных ситуаций.
Основная концепция CobiT состоит в том, что при осуществлении контроля ИТ информация рассматривается как продукт, необходимый для поддержания целей или требований бизнеса и как результат совместного применения ИТ и связанных ресурсов, которые должны управляться ИТ-процессами.
Стандарт CobiT включает в себя следующую серию книг:
1. Краткое изложение для руководства.
2. Основы.
3. Цели контроля (детализированных целей - 318 штук)
4. Руководство по управлению.
5. Руководство по проведению аудита.
6. Методики внедрения.

Стандарт CobiT выделяет 34 ИТ-процесса, объединенные в четыре следующие группы (рисунок 1.1):
1. Планирование и организация – процессы, охватывающие вопросы стратегии и тактики, а также определения путей развития ИТ, лучше всего способствующих достижению бизнес-целей.
2. Приобретение и внедрение – процессы, охватывающие вопросы разработки и приобретения решений ИТ, которые должны быть интегрированы в бизнес-процесс. Изменение существующих систем.
Cobit - «цели контроля для информации и связанных с ней технологий»
3. Эксплуатация и сопровождение – процессы, фактически предоставляющие требуемые услуги.
4. Контроль – процессы управленческого надзора и независимой оценки с привлечением внутреннего и внешнего аудита или других источников.
Для каждого из 34 ИТ-процессов определена одна цель контроля уровня ИТ-процессов (намерение или желаемый результат, который достигается посредством внедрения процедур контроля в ИТ-деятельность). Данные цели контроля в дальнейшем разбиваются на детализированные цели контроля. Таких детализированных целей в стандарте CobiT определено 318.

Рисунок 1.1. ИТ-процессы CobiT
Согласно CobiT, ИТ-процессы используются для обеспечения следующих 7 требований к информации (частично перекрывающих друг друга).
1. Полезность – информация является актуальной и соответствует БП, своевременно поставляется, непротиворечива и пригодна для использования.
2. Эффективность – предоставление информации на основе оптимального использования ресурсов.
3. Конфиденциальность – защита информации от НСД.
4. Целостность – точность и полнота информации в соответствии с бизнес-ценностями и ожиданиями.
5. Доступность – информация доступна по требованию БП в настоящее время и в будущем.
6. Соответствие требованиям – соответствие требованиям законодательства, регулирующих органов и договорных обязательств, которым подчиняются БП.
7. Достоверность – обеспечение руководства необходимой информацией для осуществления управления организацией и исполнения им обязанностей в отношении финансовой деятельности и представления отчетности регулирующим органам.
Cobit - «цели контроля для информации и связанных с ней технологий»
Цели контроля ИТ-процессов могут обеспечивать выше перечисленные требования к информации и быть основными либо второстепенными.
CobiT определяет также ИТ-ресурсы, которые задействованы в обеспечении выше указанных требований к информации. Выделено 5 классов ИТ-ресурсов:
1. Данные – информационные объекты в широком смысле, в том числе неструктурированные, графика, звук.
2. Приложения – совокупность ручных и программных процедур.
3. Технология – аппаратное обеспечение, ОС, СУБД, сети, мультимедиа, и т.д.
4. Инфраструктура – все ресурсы для размещения и поддержки ИС.
5. Персонал – включает в себя персонал и его навыки, осведомленность и умение планировать, организовывать, приобретать, поставлять, обслуживать и контролировать ИС и услуги.
Цели контроля ИТ-процессов, связь их с требованиями к информации и ИТ-ресурсами представлены на рисунке 1.2.

Рисунок 1.2. Цели контроля ИТ-процессов
Таким образом, для каждой цели контроля определяются определены основные и второстепенные требования к информации, которые они поддерживают. Также определено, какие ресурсы задействованы при обеспечении данных требований.
В книге CobiT «Руководство по управлению» вводится модель уровня развития процессов организации с оценкой уровня развития от 0 (не существующего) до 5 (оптимизированного). Данная модель зрелости в дальнейшем используется при проведении аудитов ИТ-процессов и ответа на вопрос – в какой степени ИТ-процессы соответствуют необходимым требованиям. С этой точки зрения CobiT имеет хорошие точки соприкосновения с банковским стандартом России.
В CobiT для каждого из 34 процессов вводятся ключевые показатели достижения цели. Они определяют контрольные показатели, которые постфактум сигнализируют руководству о достижении процессом ИТ требований бизнеса. Эти контрольные показатели обычно выражены такими требованиями к информации как:
Cobit - «цели контроля для информации и связанных с ней технологий»
Доступность информации необходимой для обеспечения потребностей бизнеса.
Отсутствие рисков для целостности или конфиденциальности.
Рентабельность процессов и эксплуатации.
Подтверждение надежности, полезности и соответствия требованиям.
Для каждого из 34 процессов вводятся ключевые показатели деятельности - которые свидетельствуют о том, насколько хорошо ИТ-процесс выполняет свои функции и служит достижению поставленных целей. Они являются главными показателями того, насколько поставленные цели могут быть вообще достигнуты, а также хорошими показателями существующих возможностей, практики и навыков.
Для каждого из 34 ИТ-процессов определена качественная шкала (0-5), которая указывает – в каком случае процесс нужно относить к определенной модели уровня развития.
В книге CobiT «Руководство по проведению аудита», для каждого из 34 процессов определено, каким образом оценивать уровень его соответствия установленным требованиям. Для каждого из них определены:
1. Лица организации, которых следует опросить при проведении аудита.
2. Информация и документы, которые нужно получить от опрашиваемых лиц.
3. Факторы, которые требуется оценить (вида опросного листа).
4. Факторы, которые требуется протестировать (проверить).
В книге CobiT «Методики внедрения» говорится о том, на кого надо повлиять для внедрения COBIT в организации, дается план мероприятий по внедрению COBIT. Даются опросные листы для персонала, используемые на этапе внедрения, для внутренней оценки корпоративного управления ИТ, внутренней диагностики руководства. Приведены формы по аудиту и оценке риска.
Изменение взглядов бизнеса на предоставление ИТ-услуг приводит к необходимости внедрения процесса управления их доступностью.
В третьей версии ITIL-процессы управления доступностью и непрерывностью ИТ-услуг рассматриваются вместе (далее процесс). Важнейшими ключевым понятиями этого совместного процесса являются:
доступность - способность ИТ-услуги или ее компонентов выполнять свои функции в определенный период времени;
надежность - способность ИТ-услуги или ее компонентов выполнять заданные функции при определенных условиях эксплуатации;
восстанавливаемость - способность ИТ-услуги или ее компонентов к восстановлению своих эксплуатационных характеристик, утраченных частично или полностью в результате сбоя;
обслуживаемость - характеристика ИТ-компонентов, определяющая их расположение и параметры с целью обеспечения рациональности действий персонала при монтаже, транспортировке, профилактике и ремонте (данное понятие применяется по отношению к внешним поставщикам ИТ-услуг).
Бизнес имеет свое представление о необходимой ему доступности и стоимости ИТ-услуг, а потому целью процесса является обеспечение требуемого уровня доступности с соблюдением определенного уровня затрат. Для достижения этой цели процесс направлен на выполнение следующих задач:
Планирование и разработка ИТ-услуг с учетом требований бизнеса к уровню доступности;
Оптимизация доступности ИТ-услуг путем проведения эффективных с точки зрения затрат усовершенствований;
Сокращение количества и продолжительности инцидентов, влияющих на доступность ИТ-услуг.
В ходе решения этих задач фиксируются требования бизнеса к доступности ИТ-услуг и компонентов ИТ-инфраструктуры; разрабатываются необходимые отчеты; производится периодический пересмотр уровней доступности ИТ-услуг; формируется план доступности, определяющий приоритеты и отражающий мероприятия по улучшению доступности ИТ-услуг. Иначе говоря, процесс сводится к планированию предоставления ИТ-услуг, измерению уровня доступности и проведению мероприятий по его улучшению.
Планирование
При планировании производится формулирование требований бизнеса к доступности ИТ-услуг, разрабатываются критерии определения уровня доступности и допустимого времени простоя ИТ-услуг, а также рассматриваются некоторые аспекты информационной безопасности. Бизнес должен установить границу, определяющую доступность и недоступность ИТ-услуги, например допустимое время перерыва в оказании ИТ-услуги в случае сбоя в ИТ-инфраструктуре.
При проектировании доступности ИТ-услуг проводится анализ ИТ-инфраструктуры с целью определения наиболее уязвимых компонентов, не имеющих резерва и способных в случае сбоя оказать негативное влияние на предоставление ИТ-услуг. В терминологии ITIL подобные компоненты называются Single Point of Failure (SPOF), и для их определения используется метод «Анализ влияния сбоев компонентов инфраструктуры» (Component Failure Impact Analysis, CFIA). Данный метод применяется для оценки и прогнозирования воздействия отказов ИТ-компонентов на ИТ-услугу. Основные цели CFIA таковы:
Определение точек сбоев, влияющих на доступность;
Анализ влияния сбоя компонентов на бизнес и пользователей;
Определение взаимосвязи компонентов и персонала;
Определение времени восстановления компонентов;
Определение и документирование вариантов восстановления.
Для анализа рисков используется метод анализа и управления рисками (CCTA Risk Analysis and Management Method, CRAMM), в котором анализируются возможные угрозы и зависимости ИТ-компонентов, проводится оценка вероятности возникновения нестандартных ситуаций или чрезвычайных событий.
Для обеспечения требуемого уровня доступности возможно использование техники маскирования от негативного влияния из-за планового или незапланированного простоя компонента, дублирования ИТ-компонентов, а также применение средств повышения производительности компонента в случае увеличения нагрузки и т.д. В случаях, когда конкретные бизнес-функции имеют высокую зависимость от доступности ИТ-услуг, а потери деловой репутации от простоя рассматриваются как недопустимые, устанавливаются более высокие значения доступности определенных ИТ-услуг и выделяются дополнительные ресурсы.
Проектирование предоставления ИТ-услуг гарантирует, что заявленные требования к доступности будут выполнены, но это относится к стабильному, рабочему состоянию ИТ-услуг. Однако возможны и сбои, поэтому проводится также планирование восстановления ИТ-услуг, включающее в себя организацию взаимодействия с процессом управления инцидентами и службой Service Desk; планирование и внедрение систем мониторинга для обнаружения сбоев и своевременного оповещения о них; разработку требований по резервированию и восстановлению аппаратного и программного обеспечения и данных; разработку стратегии резервного копирования и восстановления; определение метрик восстановления и т.д.
Еще один аспект планирования - определение времени простоя. Все ИТ-компоненты должны быть объектами стратегии обслуживания. В зависимости от применяемых ИТ, критичности и важности поддерживаемых конкретным ИТ-компонентом бизнес-функций частота и уровень обслуживания могут различаться. В случае необходимости предоставления услуги в режиме 24х7 следует найти оптимальный баланс между требованиями по обслуживанию ИТ-компонентов и потерями для бизнеса от простоя услуги. Утвержденные расписания обслуживания должны быть зафиксированы в соглашениях об уровне обслуживания (Service Level Agreement, SLA).
Улучшение доступности ИТ-услуг
Зачем нужно улучшать доступность? Причин может быть множество: несоответствие качества ИТ-услуг требованиям SLA; нестабильность предоставления ИТ-услуг; тенденции к снижению уровня доступности ИТ-услуг; недопустимо большие сроки восстановления; запросы со стороны бизнеса на увеличение уровня доступности.
Улучшение доступности требует обоснованных дополнительных финансовых затрат, и для установления возможности улучшения ИТ-услуг используются определенные методы и технологии, среди них анализ дерева отказов (Fault Tree Analysis, FTA) и анализ системных простоев (Systems Outage Analysis, SOA).
Анализ дерева отказов определяет цепь событий, приводящих к отказу ИТ-компонента или ИТ-услуги. Графически дерево отказов (см. рис.) представляет собой последовательность событий, которая начинается с инициирующего события, сопровождаемого одним или несколькими функциональными событиями, и заканчивается финальным состоянием. В зависимости от событий, последовательности могут логически разветвляться.
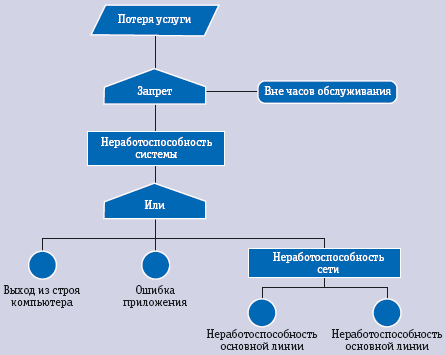
Анализ системных простоев представляет собой структурированный подход к идентификации основных причин прерывания в предоставлении ИТ-услуг и использует несколько источников данных для определения места и причины возникновения прерываний. Цели такого анализа:
Определение основных причин сбоев предоставления ИТ-услуг;
Определение эффективности поддержки ИТ-услуг;
Подготовка отчетов;
Инициирование программы по исполнению принятых рекомендаций;
Анализ улучшений уровня доступности, полученного с помощью анализа системных простоев.
Использование анализа системных простоев позволит повысить уровень доступности без увеличения затрат, улучшить собственные навыки персонала и способности, позволяющие избежать затрат на консультирование по вопросам улучшения доступности, определить конкретную программу улучшений.
Результатом деятельности по улучшению доступности услуг является долгосрочный план проактивного улучшения доступности ИТ-услуг с учетом финансовых ограничений. План доступности описывает текущие и запланированные уровни доступности, а также мероприятия, которые нужно проводить для ее улучшения. В подготовке плана необходимо участие представителей бизнеса, менеджеров внедренных процессов ITSM, представителей внешних поставщиков ИТ-услуг, технических специалистов поддержки, ответственных за тестирование и обслуживание. План составляется на срок до двух лет, а на ближайшие шесть месяцев он должен содержать подробное описание мероприятий. План пересматривается каждый квартал с минимальными корректировками и раз в полгода с возможностью внесения серьезных изменений.
Измерение доступности ИТ-услуг
ИТ-услуга с точки зрения потребителя может считаться доступной, когда жизненно важные функции бизнеса, ее использующие, выполняются нормально. При этом основными количественными показателями являются доступность - отношение времени реальной доступности ИТ-компонента ко времени доступности, определенному в соглашениях об уровне обслуживания, и недоступность (в %) - инверсия доступности. Эти параметры используются ИТ-службами и, с точки зрения бизнеса, не очень показательны, так как не отражают значения доступности для бизнеса или пользователей - они могут демонстрировать высокий уровень доступности ИТ-компонентов, в то время как актуальный уровень доступности ИТ-услуг будет низок.
Понятными бизнесу могут быть такие показатели, как: частота простоев ИТ-услуг, общая длительность простоя, область влияния от прерывания ИТ-услуги.
Роли и ответственности
В рамках процесса определяется роль менеджера процесса, в обязанности которого входит руководство процессом и выполнение необходимых действий. Менеджер процесса отвечает за функционирование и развитие процесса в соответствии с регламентирующими документами и планами. На роль менеджера процесса рекомендуется принимать сотрудника, имеющего практический опыт процессного управления, знающего ITSM, статистические и аналитические методы, применяемые в ИТ, принципы управления затратами, имеющего опыт работы с персоналом, владеющего методами проведения переговоров и т.д.
Внедрение процесса
Внедрение любого процесса ITSM - длительный и сложный проект, имеющий определенные цели и сроки. Внедрение собственными силами затруднительно: внедрение процесса параллельно с ежедневной операционной деятельностью не позволяет полностью сфокусироваться на проекте; постоянное «оттягивание» ресурсов на посторонние по отношению к проекту задачи в конечном результате приводит к росту финансовых затрат, сдвигу сроков проекта на неопределенный период, постепенной потере внимания или даже возможной остановке проекта. Кроме того, внедрение собственными силами требует знаний в данной предметной области, что влечет за собой необходимость проведения дорогостоящего обучения.
Как и любой проект, внедрение процесса начинается с создания проектных команд, разработки документов по управлению проектом, составления плана проекта и т.д. На этапе «предпроектных» работ проводятся маркетинговые мероприятия по ознакомлению представителей бизнеса с технологиями и рекомендациями ITIL и обоснованию необходимости для бизнеса внедрения процесса управления доступностью ИТ-услуг.
После согласования и получения положительного ответа о внедрении процесса определяются цели и границы предметной области процесса.
Эффект и проблемы
Основным эффектом от внедрения процесса является то, что ИТ-услуги разрабатываются с учетом требований к доступности, и их операционная деятельность и управление осуществляется на согласованном уровне доступности и в рамках определенных затрат. Положительными факторами также являются: наличие одного ответственного за доступность ИТ-услуг; оптимальное использование производительности ИТ-инфраструктуры для обеспечения требуемого уровня доступности ИТ-услуг; уменьшение частоты и длительности отказов ИТ-услуг с течением времени; качественный переход в деятельности поставщиков ИТ-услуг от устранения ошибок в предоставлении услуг к повышению уровня их доступности.
Возможные проблемы, которые могут негативным образом влиять на принятие решения о внедрении и функционировании процесса, обычно носят организационный характер:
Наличие ситуации, когда каждый ИТ-менеджер отвечает за доступность ИТ-систем или компонентов, находящихся в сфере его ответственности, в то время как общая доступность ИТ-услуг не отслеживается и может быть неудовлетворительной;
Отказ от внедрения процесса по причине того, что текущая доступность ИТ-услуг считается приемлемой;
Предположения, что при наличии других внедренных процессов ITSM процесс управления доступностью будет выполнен автоматически;
Сопротивление централизации в управлении ИТ-инфраструктурой со стороны ИТ-менеджеров;
Недостаточность полномочий менеджера процесса, приводящая к отсутствию возможности выполнения им обязанностей должным образом.
Евгений Булычев ([email protected]) - консультант отделения «Ай-Теко Бизнес Консалтинг» (Москва).
Последнее время я все больше укрепляюсь в давно блуждающей в моей голове и довольно еретической мысли: классический показатель доступности малопригоден для измерения и оценки доступности ИТ-услуг в реальном мире. И в ряде случаев от него можно легко отказаться. Эти случаи касаются в первую очередь измерения доступности услуг типа « » (фактически речь идет об ИТ-доступности бизнес-процессов). Попробую обосновать и буду рад услышать возражения.
Полагаю, всем читателям портала знакома формула:
Availability = (AST — DT)/AST ,
где AST - согласованное время предоставления услуги, DT - сумма простоев за период.
А также, вероятно, знакомы сложности ее применения:
Первая сложность связана с обсуждением показателя. Доступность определена как 99,9%. Вроде неплохо. Но 0,1% в год равен почти 9 часам. А в месяц - это почти 45 минут. А в неделю - чуть более 10 минут. Так какие 99,9% имел в виду заказчик? А сервис-провайдер?
Однако значительно более существенен следующий нюанс: показатель довольно неточно отражает негативное влияние на бизнес. Что если все без малого 9 часов за год случились разом? Или услуга становилась недоступна потребителям по две минуты, но 15 раз за один день? Как это будет выражено в процентах?.. Поэтому, например, ITIL вводит такие показатели, как MTRS, MTBF, MTBSI.
Однако предлагаю вернуться в начало координат и задаться вопросом, а зачем мы вообще вводим показатели доступности? Почему бизнес предъявляет требования к доступности услуг? Почему сервис-провайдер должен обеспечивать высокую доступность и отчитываться по ее фактическим значениям? Ответ прост: бизнес несет потери вследствие простоев ИТ-услуг. Значит, идеальным для бизнеса показателем доступности, вероятно, была бы метрика «Потери вследствие простоев ИТ-услуг»?
Сильно выручила бы такая метрика и сервис-провайдера. Ведь это готовый ответ на вопрос о бизнес-рисках, связанных с нарушениями ИТ-доступности. И, следовательно, у сервис-провайдера появляется возможность:
- более прозрачно транслировать требования доступности бизнес-процессов к ИТ-инфраструктуре;
- более обоснованно принимать решения по мерам, направленным на повышение надежности и отказоустойчивости ИТ-систем;
- более обоснованно оценивать успешность мер по итогам их реализации.
Но, конечно, произвести расчет такой метрики сложно, порой невозможно. Таким образом, мы должны определить другие показатели, не забывая о том, что в совокупности они должны нести информацию о бизнес-влиянии (фактическом или потенциальном).
От чего зависят потери бизнеса вследствие простоев?
- Чем меньше за отчетный период услуга была в uptime, тем больше потери. Введем показатель «Суммарное время простоев».
- Чем дольше разовый простой, тем больше потери. Нередко потери не являются постоянной во времени величиной и зависят от длительности прерывания экспоненциально. В первый отрезок времени ущерб складывается из несовершенных транзакций, потерь продуктивности персонала и затрат на восстановление, но с определенного момента длительный простой угрожает бизнесу штрафами, санкциями, уроном репутации и так далее. Введем показатель «Максимальный разовый простой».
- Ряд бизнес-процессов, напротив, «чувствительны» не к единичным длительным простоям, а к частым прерываниям. Это особенно важный фактор для процессов, в рамках которых происходят длительные вычисления, которые в случае прерывания требуется перезапускать. Таким образом, должно быть обеспечено как можно меньшее количество прерываний за период. Введем показатель «Количество нарушений».
Альтернативной (или дополнительной) метрикой, отражающей тот же аспект, но с акцентом на периоде спокойной работы пользователей, может быть показатель «Минимальная (или средняя) продолжительность работы без нарушений».
Представленные показатели в совокупности, кажется, отражают характер того, как бизнес несет потери вследствие простоев ИТ-услуг. Поэтому далее остается только известным способом выполнить нормирование и агрегирование. Да, полученный показатель будет также выражен в процентах, но это будут уже совсем другие проценты.
При этом не обязательно для каждой ИТ-услуги использовать все три (или четыре) метрики. В зависимости от того, чувствителен ли бизнес к частым нарушениям данной ИТ-услуги или, напротив, для него критичны длительные разовые нарушения, часть показателей могут быть опущены или включены в расчет с меньшим весом.
От представленных метрик можно легко перейти к известным MTRS, MTBF, MTBSI и, конечно, классическому показателю доступности. Но, на мой взгляд, предложенный набор скажет заказчику и сервис-провайдеру несколько больше о бизнес-влиянии нарушений ИТ-доступности. Или нет?
Отчаянно нуждаюсь в возражениях. Почему от классического показателя доступности услуги, выраженной в процентах, ни в коем случае нельзя отказываться? Есть ли такой показатель в ваших отчетах? О чем и кому он говорит?