Дисперсионный анализ (ANOVA). Факторный анализ прибыли Факторный анализ статистические методы и практические вопросы
Statistica 6 q. Подготовка корреляционной матрицы для факторного анализа q. Создание матрицы для факторного анализа q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы
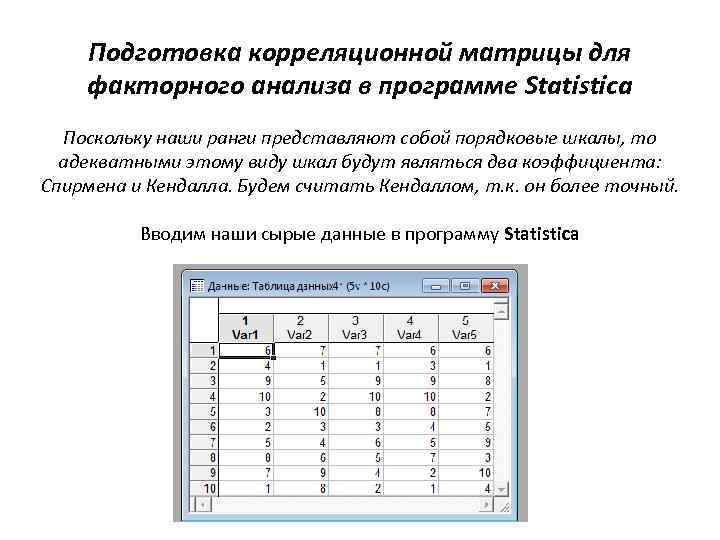 Подготовка корреляционной матрицы для факторного анализа в программе Statistica Поскольку наши ранги представляют собой порядковые шкалы, то адекватными этому виду шкал будут являться два коэффициента: Спирмена и Кендалла. Будем считать Кендаллом, т. к. он более точный. Вводим наши сырые данные в программу Statistica
Подготовка корреляционной матрицы для факторного анализа в программе Statistica Поскольку наши ранги представляют собой порядковые шкалы, то адекватными этому виду шкал будут являться два коэффициента: Спирмена и Кендалла. Будем считать Кендаллом, т. к. он более точный. Вводим наши сырые данные в программу Statistica




 Мы получили факторную матрицу, рассчитанную коэффициентом Кендалла, т. к. именно он является адекватным для наших данных, которые представляют собой шкалы порядка.
Мы получили факторную матрицу, рассчитанную коэффициентом Кендалла, т. к. именно он является адекватным для наших данных, которые представляют собой шкалы порядка.
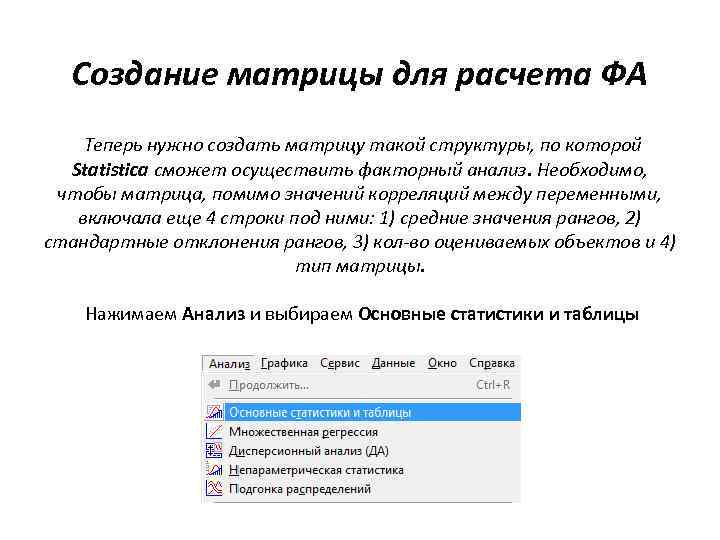 Создание матрицы для расчета ФА Теперь нужно создать матрицу такой структуры, по которой Statistica сможет осуществить факторный анализ. Необходимо, чтобы матрица, помимо значений корреляций между переменными, включала еще 4 строки под ними: 1) средние значения рангов, 2) стандартные отклонения рангов, 3) кол-во оцениваемых объектов и 4) тип матрицы. Нажимаем Анализ и выбираем Основные статистики и таблицы
Создание матрицы для расчета ФА Теперь нужно создать матрицу такой структуры, по которой Statistica сможет осуществить факторный анализ. Необходимо, чтобы матрица, помимо значений корреляций между переменными, включала еще 4 строки под ними: 1) средние значения рангов, 2) стандартные отклонения рангов, 3) кол-во оцениваемых объектов и 4) тип матрицы. Нажимаем Анализ и выбираем Основные статистики и таблицы


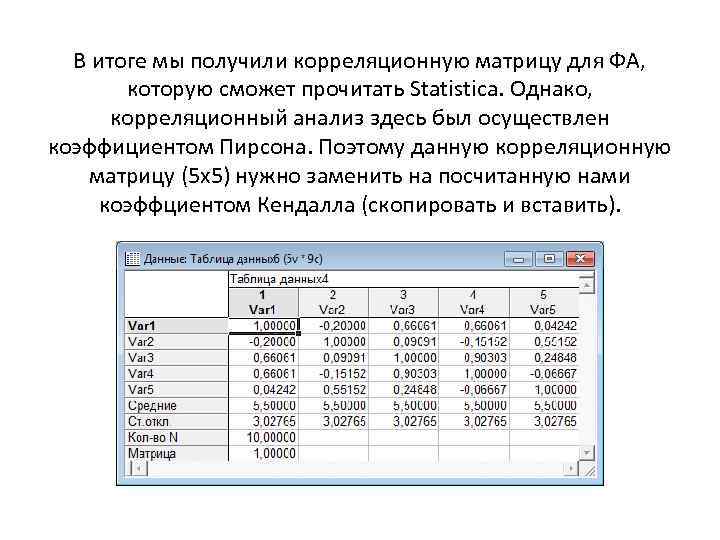 В итоге мы получили корреляционную матрицу для ФА, которую сможет прочитать Statistica. Однако, корреляционный анализ здесь был осуществлен коэффициентом Пирсона. Поэтому данную корреляционную матрицу (5 х5) нужно заменить на посчитанную нами коэффциентом Кендалла (скопировать и вставить).
В итоге мы получили корреляционную матрицу для ФА, которую сможет прочитать Statistica. Однако, корреляционный анализ здесь был осуществлен коэффициентом Пирсона. Поэтому данную корреляционную матрицу (5 х5) нужно заменить на посчитанную нами коэффциентом Кендалла (скопировать и вставить).
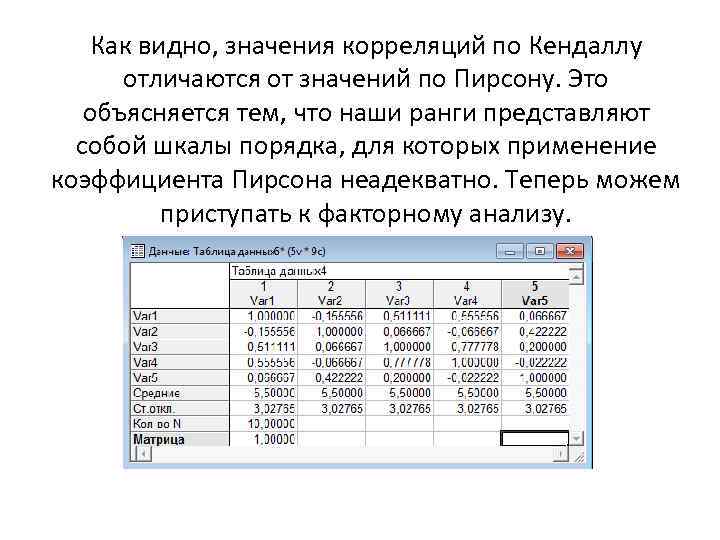 Как видно, значения корреляций по Кендаллу отличаются от значений по Пирсону. Это объясняется тем, что наши ранги представляют собой шкалы порядка, для которых применение коэффициента Пирсона неадекватно. Теперь можем приступать к факторному анализу.
Как видно, значения корреляций по Кендаллу отличаются от значений по Пирсону. Это объясняется тем, что наши ранги представляют собой шкалы порядка, для которых применение коэффициента Пирсона неадекватно. Теперь можем приступать к факторному анализу.

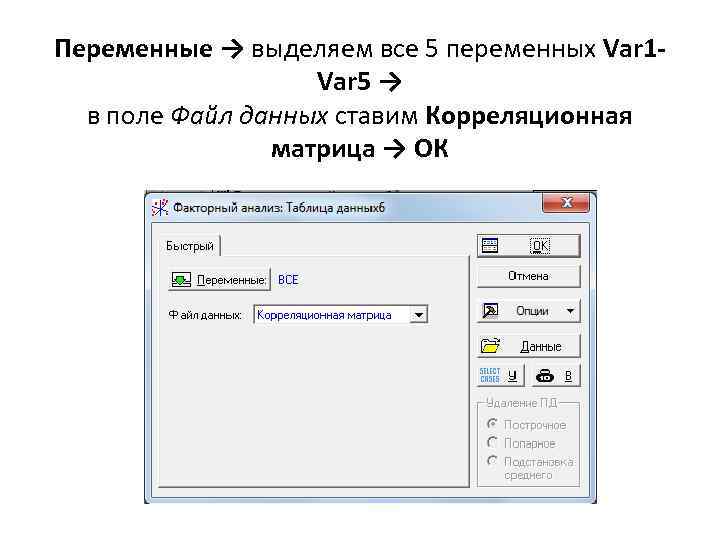 Переменные → выделяем все 5 переменных Var 1 Var 5 → в поле Файл данных ставим Корреляционная матрица → ОК
Переменные → выделяем все 5 переменных Var 1 Var 5 → в поле Файл данных ставим Корреляционная матрица → ОК
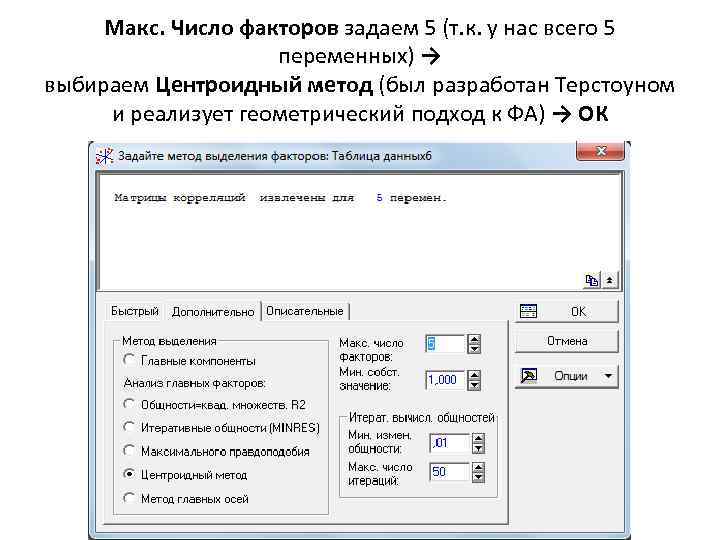 Макс. Число факторов задаем 5 (т. к. у нас всего 5 переменных) → выбираем Центроидный метод (был разработан Терстоуном и реализует геометрический подход к ФА) → ОК
Макс. Число факторов задаем 5 (т. к. у нас всего 5 переменных) → выбираем Центроидный метод (был разработан Терстоуном и реализует геометрический подход к ФА) → ОК
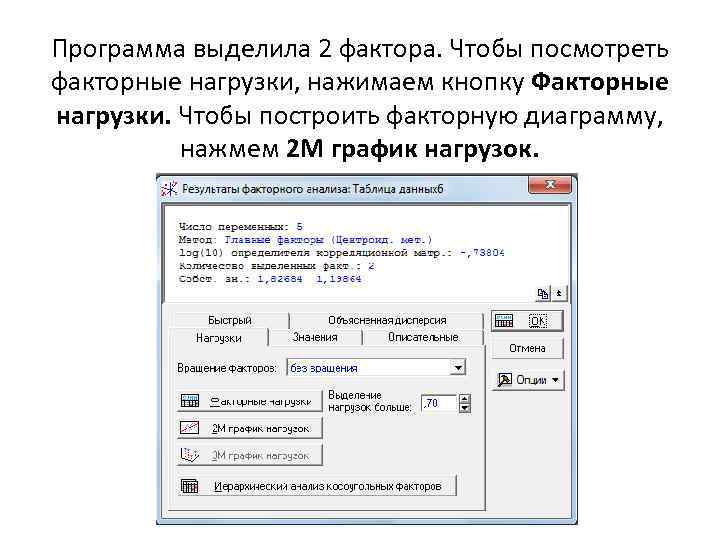 Программа выделила 2 фактора. Чтобы посмотреть факторные нагрузки, нажимаем кнопку Факторные нагрузки. Чтобы построить факторную диаграмму, нажмем 2 М график нагрузок.
Программа выделила 2 фактора. Чтобы посмотреть факторные нагрузки, нажимаем кнопку Факторные нагрузки. Чтобы построить факторную диаграмму, нажмем 2 М график нагрузок.


 Statgraphics Centurion q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы q. Построение объектной диаграммы
Statgraphics Centurion q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы q. Построение объектной диаграммы
 В программе не предусмотрена возможность заложить свою корреляционную матрицу, поэтому начинаем сразу с анализа наших рангов. Вбиваем наши ранги и выбираем Analyze → Variable Data → Multivariate Methods → Factor Analysis
В программе не предусмотрена возможность заложить свою корреляционную матрицу, поэтому начинаем сразу с анализа наших рангов. Вбиваем наши ранги и выбираем Analyze → Variable Data → Multivariate Methods → Factor Analysis
 В итоге, программа выделила нам 2 фактора с уровнем объясненной дисперсии 82, 468 %. Это значит, что этими факторами объясняется 82, 468 % (почти 4/5) всей нашей информации по пяти переменным.
В итоге, программа выделила нам 2 фактора с уровнем объясненной дисперсии 82, 468 %. Это значит, что этими факторами объясняется 82, 468 % (почти 4/5) всей нашей информации по пяти переменным.
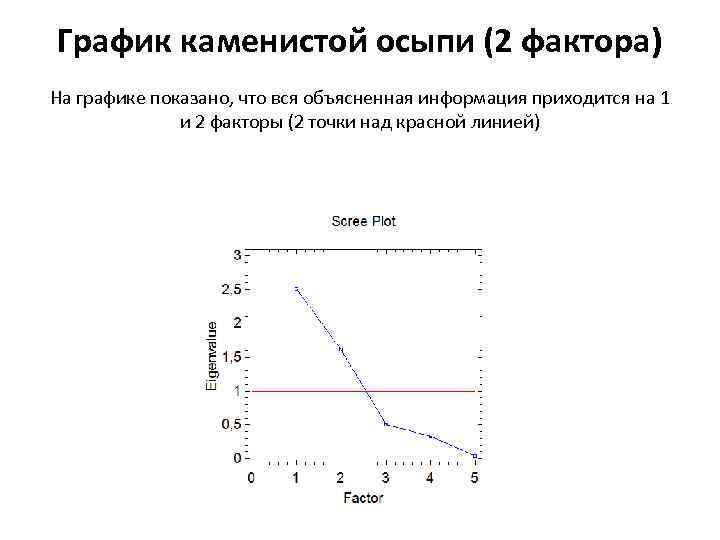 График каменистой осыпи (2 фактора) На графике показано, что вся объясненная информация приходится на 1 и 2 факторы (2 точки над красной линией)
График каменистой осыпи (2 фактора) На графике показано, что вся объясненная информация приходится на 1 и 2 факторы (2 точки над красной линией)
 Факторные нагрузки Нажимаем Tables (вторая кнопка слева на панели) Ставим галочку возле Extraction Statistics → ОК
Факторные нагрузки Нажимаем Tables (вторая кнопка слева на панели) Ставим галочку возле Extraction Statistics → ОК
 Как видно факторные нагрузки на уровне десятых отличаются от тех, что мы получили при ручном расчете и в Statistica. Объясняется это тем, что в Statgraphics нельзя заложить свою корреляционную матрицу и программа всегда считает коэффициентом Пирсона, что не адекватно для данных в шкалах порядка.
Как видно факторные нагрузки на уровне десятых отличаются от тех, что мы получили при ручном расчете и в Statistica. Объясняется это тем, что в Statgraphics нельзя заложить свою корреляционную матрицу и программа всегда считает коэффициентом Пирсона, что не адекватно для данных в шкалах порядка.
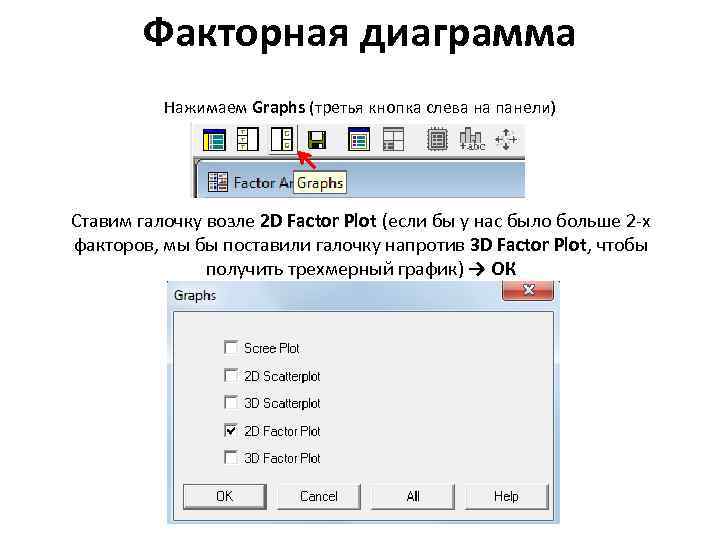 Факторная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Factor Plot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Factor Plot, чтобы получить трехмерный график) → ОК
Факторная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Factor Plot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Factor Plot, чтобы получить трехмерный график) → ОК
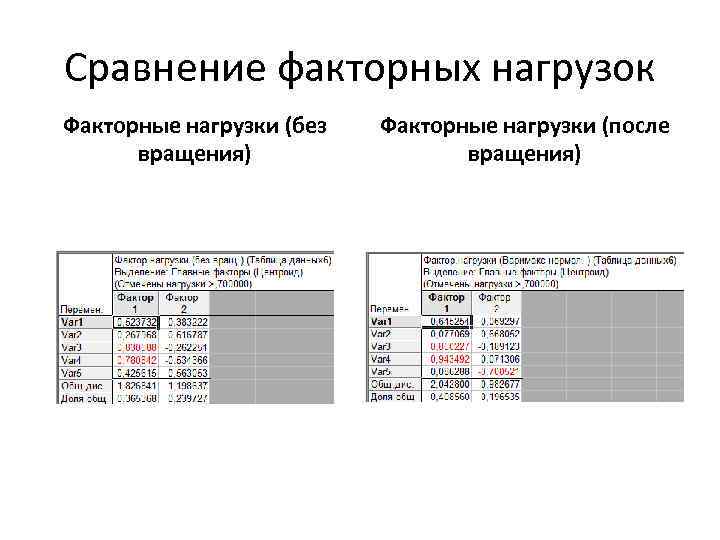
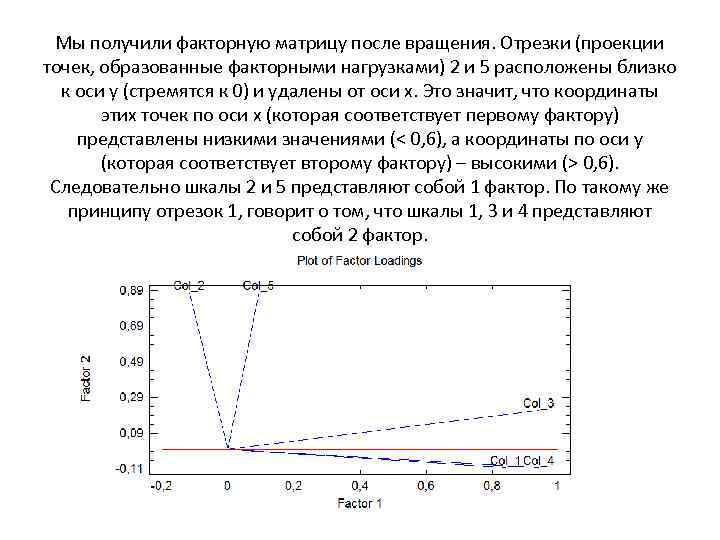 Мы получили факторную матрицу после вращения. Отрезки (проекции точек, образованные факторными нагрузками) 2 и 5 расположены близко к оси y (стремятся к 0) и удалены от оси x. Это значит, что координаты этих точек по оси x (которая соответствует первому фактору) представлены низкими значениями (0, 6). Следовательно шкалы 2 и 5 представляют собой 1 фактор. По такому же принципу отрезок 1, говорит о том, что шкалы 1, 3 и 4 представляют собой 2 фактор.
Мы получили факторную матрицу после вращения. Отрезки (проекции точек, образованные факторными нагрузками) 2 и 5 расположены близко к оси y (стремятся к 0) и удалены от оси x. Это значит, что координаты этих точек по оси x (которая соответствует первому фактору) представлены низкими значениями (0, 6). Следовательно шкалы 2 и 5 представляют собой 1 фактор. По такому же принципу отрезок 1, говорит о том, что шкалы 1, 3 и 4 представляют собой 2 фактор.
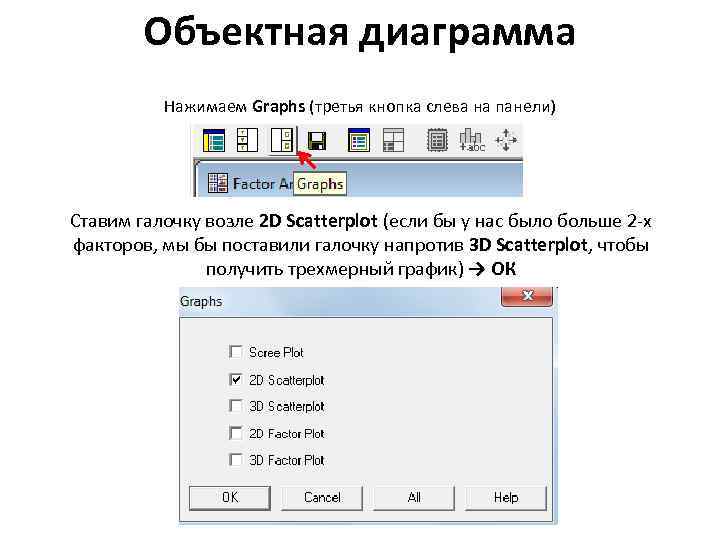 Объектная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Scatterplot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Scatterplot, чтобы получить трехмерный график) → ОК
Объектная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Scatterplot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Scatterplot, чтобы получить трехмерный график) → ОК
Общие определения
Целью дисперсионного анализа (ANOVA – Analysis of Variation) является проверка значимости различия между средними в разных группах с помощью сравнения дисперсий этих групп. Разделение общей дисперсии на несколько источников (связанных с различными эффектами в плане), позволяет сравнить дисперсию, вызванную различием между группами, с дисперсией, вызванной внутригрупповой изменчивостью.
Проверяемая гипотеза состоит в том, что различия между группами нет. При истинности нулевой гипотезы, оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии. При ложности - значимо отклоняться.
В целом дисперсионный анализ может быть разделён на несколько видов:
одномерный (одна зависимая переменная) и многомерный (несколько зависимых переменных);
однофакторный (одна группирующая переменная) и многофакторный (несколько группирующих переменных) с возможным взаимодействием между факторами;
с простыми измерениями (зависимая переменная измеряется лишь один раз) и с повторными (зависимая переменная измеряется несколько раз).
В STATISITICA реализованы все известные модели дисперсионного анализа.
В STATISITICA дисперсионный анализ можно провести с помощью модуля Дисперсионный анализ в блоке STATISITICA Base (Анализ -> Дисперсионный анализ(ДА)) . Для построения модели специального вида используется полная версия Дисперсионного анализа, представленная в модулях Общие линейные модели , Обобщённые линейные и нелинейные модели , Общие регрессионные модели , Общие модели частных наименьших квадратов из блока Углубленные методы анализа (STATISTICA Advanced Linear/Non-Linear Models ).
в начало
Пошаговый пример в STATISTICA
Мы будем иллюстрировать возможности дисперсионного анализа в STATISITICA , рассматривая пошаговый модельный пример.
Исходный файл данных описывает совокупность людей с разным уровнем дохода, образования, возраста и пола. Рассмотрим, как влияют уровень образования, возраст и пол на уровень дохода.
По возрасту все люди были разделены на четыре группы:
до 30 лет;
от 31 до 40 лет;
от 41 до 50 лет;
от 51 года.
По уровню образования произошло деление на 5 групп:
незаконченное среднее;
среднее;
среднее профессиональное;
незаконченное высшее;
высшее.
Так как данные модельные, то полученные результаты будут носить в основном качественный характер и иллюстрировать способ проведения анализа.
Шаг 1. Выбор анализа
Выберем дисперсионный анализ из меню: Анализ -> Углубленные методы анализа -> Общие линейные модели .
Рис. 1. Выбор дисперсионного анализа из выпадающего меню STATISTICA
Далее откроется окно, в котором представлены различные виды анализа. Выбираем Вид анализа – Факторный Дисперсионный анализ .

Рис. 2. Выбор вида анализа
В этом окне также можете выбрать способ построения модели: диалоговый режим или использовать мастер анализа. Выберем диалоговый режим.
Шаг 2. Задание переменных
Из открытого файла данных выберем переменные для анализа, щелкните кнопку Переменные , выберете:
Доход – зависимая переменная,
Уровень образования , Пол и Возраст – категориальные факторы (предикторы).
Заметим, что Коды факторов в этом простом примере можно не задавать. При нажатии на кнопку OK , STATISTICA задаст их автоматически.

Рис. 3. Задание переменных
Шаг 3. Изменение опций
Обратимся к вкладке Опции в окне GLM Факторный ДА .

Рис. 4. Вкладка Опции
В этом диалоговом окне вы можете:
выбрать случайные факторы;
задать тип параметризации модели;
указать тип сумм квадратов (SS), имеется 6 различных сумм квадратов (SS);
включить проведение кросс-проверки.
Оставим все установки по умолчанию (этого достаточно в большинстве случаев) и нажмём кнопку ОК .
Шаг 4. Анализ результатов – просмотр всех эффектов
Результаты анализа можно посмотреть в окне Результаты с помощью вкладок и группы кнопок. Рассмотрим, например, вкладку Итоги .

Рис. 5. Окно анализа результатов: вкладка Итоги
С этой вкладки можно получить доступ ко всем основным результатам. Воспользуйтесь остальными вкладками для получения дополнительных результатов. Кнопка Меньше позволяет изменить диалоговое окно результатов, удалив вкладки, которые, как правило, не используются.
При нажатии кнопки Проверить все эффекты получаем следующую таблицу.

Рис. 6. Таблица всех эффектов
Эта таблица выводит основные результаты анализа: суммы квадратов, степени свободы, значения F-критерия, уровни значимости.
Для удобства исследования значимые эффекты (p<.05) выделены красным цветом. Два главных эффекта (Уровень образования и Возраст ) и некоторые взаимодействия в данном примере являются значимыми (p<.05).
Шаг 5. Анализ результатов – просмотр заданных эффектов
Чтобы посмотреть, каким образом средний уровень дохода различается по категориям, удобнее всего воспользоваться графическими средствами. При нажатии на кнопку Все эффекты/графики появится следующее диалоговое окно.

Рис. 7. Окно Таблица всех эффектов
В окне перечислены все рассматриваемые эффекты. Статистически значимые эффекты помечены *.
Например, выберем эффект Возраст , в группе Отображать укажем Таблицу и нажмём ОК . Появится таблица, в которой для каждого уровня эффекта приведено среднее значение зависимой переменной (Доход) , величина стандартной ошибки и границы доверительных пределов.

Рис. 8. Таблица с описательными статистиками по уровням переменной Возраст
Эту таблицу удобно представить в графическом виде. Для этого выберем График в группе Отображать диалогового окна Таблица всех эффектов и нажмём ОК . Появится соответствующий график.

Рис. 9. График зависимости среднего дохода от возраста
Из графика ясно видно, что между группами людей разного возраста есть разница в уровне дохода. Чем выше возраст, тем больше доход.
Аналогичные операции проведём для взаимодействия нескольких факторов. В диалоговом окне выберем Пол *Возраст и нажмём ОК .

Рис. 10. График зависимости среднего дохода от пола и возраста
Получен неожиданный результат: для опрошенных людей в возрасте до 50 лет уровень дохода растёт с возрастом и не зависит от пола; для опрошенных людей старше 50 лет женщины имеют значимо больший доход, чем мужчины.
Стоит построить полученный график в разрезе уровня образования. Возможно, такая закономерность нарушается в некоторых категориях или, наоборот, носит универсальный характер. Для этого выберем Уровень образования * Пол * Возраст и нажмём ОК .

Рис. 11. График зависимости среднего дохода от пола, возраста, уровня образования
Видим, что полученная зависимость не характерна для среднего и среднего профессионального образования. В остальных случаях она справедлива.
Шаг 6. Анализ результатов – оценка качества модели
Выше в основном использовались графические средства дисперсионного анализа. Рассмотрим некоторые другие полезные результаты, которые можно получить.
Во-первых, интересно посмотреть, какую долю изменчивости объясняют рассматриваемые факторы и их взаимодействия. Для этого во вкладке Итоги нажмём на кнопку Общая R модели . Появится следующая таблица.
Рис. 12. Таблица SS модели и SS остатков
Число в столбце Множеств. R2 – квадрат множественного коэффициента корреляции; оно показывает, какую долю изменчивости объясняет построенная модель. В нашем случае R2 = 0.195, что говорит о невысоком качестве модели. В самом деле, на уровень дохода влияют не только факторы, внесённые в модель.
Шаг 7. Анализ результатов – анализ контрастов
Часто требуется не только установить различие в среднем значении зависимой переменной для разных категорий, но и установить величину различия для заданных категорий. Для этого следует исследовать контрасты.
Выше было показано, что уровень дохода для мужчин и женщин значимо отличается для возраста от 51, в остальных случаях различие не значимо. Выведем разницу в уровне дохода для мужчин и женщин в возрасте выше 51 года и между 40 и 50 годами.
Для этого перейдём во вкладку Контрасты и выставим все значения следующим образом.

Рис. 13. Вкладка Контрасты
При нажатии кнопки Вычислить появится несколько таблиц. Нас интересует таблица с оценками контрастов.

Рис. 14. Таблица Оценки контрастов
Можно сделать следующие выводы:
для мужчин и женщин старше 51 года разница в уровне дохода составляет 48,7 тыс. долл. Разница значима;
для мужчин и женщин в возрасте от 41 до 50 лет разница в уровне дохода составляет 1,73 тыс. долл. Разница не значима.
Аналогично можно задать более сложные контрасты или воспользоваться одним из заранее заданных наборов.
Шаг 8. Дополнительные результаты
Используя остальные вкладки окна результатов можно получить следующие результаты:
средние значения зависимой переменной для выбранного эффекта – вкладка Средние ;
проверка апостериорных критериев (post hoc) – вкладка Апостериорные ;
проверка сделанных для проведения дисперсионного анализа предположений – вкладка Предположения ;
построение профилей отклика/желательности – вкладка Профили ;
анализ остатков – вкладка Остатки ;
вывод матриц, используемых в анализе – вкладка Матрицы ;
-
Называют факторным анализом . Основными разновидностями факторного анализа являются детерминированный анализ и стохастический анализ.
Детерминированный факторный анализ основывается на методике изучения влияния таких факторов, взаимосвязь которых с обобщающим экономическим показателем является функциональной. Последнее означает, что обобщающий показатель представляет собой либо произведение, либо частное от деления, либо алгебраическую сумму отдельных факторов.
Стохастический факторный анализ основывается на методике исследования влияния таких факторов, взаимосвязь которых с обобщающим экономическим показателем является вероятностной, иначе — корреляционной.
В условиях наличия функциональной взаимосвязи с изменением аргумента всегда имеет место и соответствующе изменение функции. При наличии же вероятностной взаимосвязи изменение аргумента может сочетаться с несколькими значениями изменения функции.
Факторный анализ подразделяется также на прямой , иначе дедуктивный анализ и обратный (индуктивный) анализ.
Первый вид анализа осуществляет изучение влияния факторов дедуктивным методом, то есть в направлении от общего к частному. При обратном факторном анализе влияние факторов исследуется индуктивным методом — в направлении от частных факторов к обобщающим экономическим показателям.
Классификация факторов, влияющих на эффективности деятельности организации
Факторы, влияние которых изучается при проведении , классифицируются по различным признакам. Прежде всего их можно подразделить на два основных вида: внутренние факторы , зависящие от деятельности данной , и внешние факторы , не зависящие от данной организации.
Внутренние факторы в зависимости от величины их воздействия на , можно подразделить на главные и второстепенные. К числу главных относятся факторы, связанные с использованием , и материалов, а также факторы, обусловленные снабженческо-сбытовой деятельностью и некоторыми другими сторонами функционирования организации. Главные факторы оказывают основополагающее воздействие на обобщающие экономические показатели. Внешние факторы, не зависящие от данной организации, обусловлены природно-климатическими (географическими), социально-экономическими, а также внешнеэкономическими условиями.
В зависимости от длительности их воздействия на экономические показатели можно выделить постоянные и переменные факторы . Первый вид факторов оказывает влияние на экономические показатели, которое не ограничено во времени. Переменные факторы воздействуют на экономические показатели лишь в течение определенного периода времени.
Факторы могут подразделяться на экстенсивные (количественные) и интенсивные (качественные) по признаку сущности их влияния на экономические показатели. Так, например, если изучается влияние на объем выпуска продукции трудовых факторов, то изменение численности рабочих будет являться экстенсивным фактором, а изменение производительности труда одного рабочего — интенсивным факторов.
Факторы, влияющие на экономические показатели, по степени их зависимости от воли и сознания работников организации и других лиц, могут подразделяться на объективные и субъективные факторы . К объективными факторам могут быть отнесены погодные условия, стихийные бедствия, которые не зависят от деятельности человека. Субъективные же факторы целиком и полностью зависят от людей. Подавляющее большинство факторов следует отнести к числу субъективных.
Факторы можно подразделить также в зависимости от сферы их действия на факторы неограниченного и факторы ограниченного действия. Первый вид факторов действует повсеместно, в любых отраслях народного хозяйства. Второй вид факторов оказывает влияние лишь внутри какой-либо отрасли или даже отдельной организации.
По своей структуре факторы подразделяются на простые и сложные. Подавляющая часть факторов — сложные, включающие в себя несколько составных частей. Вместе с тем имеются и такие факторы, которые не поддаются расчленению. Например, фондоотдача может служить примером сложного фактора. Количество дней, отработанных оборудованием за данный период является простым фактором.
По характеру влияния на обобщающие экономические показатели различают прямые и косвенные факторы . Так, изменение проданной продукции, хотя оно и оказывает обратное влияние на величину прибыли, следует считать прямым факторам, то есть фактором первого порядка. Изменение же величины материальных затрат оказывает на прибыль косвенное влияние, т.е. воздействует на прибыль не непосредственно, а через себестоимость, представляющую собой фактор первого порядка. Исходя из этого уровень материальных затрат следует считать фактором второго порядка, то есть косвенным фактором.
В зависимости от того, можно ли дать количественную оценку влияния данного фактора на обобщающий экономический показатель, различают измеряемые и неизмеряемые факторы.
Эта классификация тесно взаимосвязана с классификацией резервов повышения эффективности хозяйственной деятельности организаций, или, иначе говоря, резервов улучшения анализируемых экономических показателей.
Факторный экономический анализ
В те признаки, которые характеризуют причину, носят название факторных, независимых. Те же признаки, которые, характеризуют следствие, принято называть результатными, зависимыми.
Совокупность факторных и результативных признаков, которые находятся в одной причинно-следственной связи, носит название факторной системы . Существует также понятие модели факторной системы. Она характеризует взаимосвязь между результативным признаком, обозначаемым как y, и факторными признаками, обозначаемыми как . Иными словами, модель факторной системы выражает взаимосвязь между обобщающим экономическим показателям и отдельными факторами, влияющими на этот показатель. При этом в качестве факторов выступают другие экономические показатели, представляющие собой причины изменения обобщающего показателя.
Модель факторной системы математически может быть выражена при помощи следующей формулы:
Установление зависимостей между обобщающими (результативными) и влияющими на них факторами носит название экономико-математического моделирования.
В изучается два вида взаимосвязей между обобщающими показателями и влияющими на них факторами:
- функциональная (иначе — функционально-детерминированная, или жестко детерминированная связь.)
- стохастическая (вероятностная) связь.
Функциональная связь — это такая связь, при которой каждому значению фактора (факторного признака) соответствует вполне определенное неслучайное значение обобщающего показателя (результативного признака).
Стохастическая связь — это такая связь, при которой каждому значению фактора (факторного признака) соответствует множество значений обобщающего показателя (результативного признака). В этих условиях для каждого значения фактора x значения обобщающего показателя y образуют условное статистическое распределение. Вследствие этого изменение значения фактора x только в среднем вызывает изменение обобщающего показателя y.
В соответствии с двумя рассмотренными типами взаимосвязей различают методы детерминированного факторного анализа и методы стохастического факторного анализа. Рассмотрим следующую схему:
Методы, применяемые в факторном анализе. Схема №2Наибольшую полноту и глубину аналитического исследования, наибольшую точность результатов анализа обеспечивает применение экономико-математических методов исследования.
Эти методы имеют ряд преимуществ перед традиционными и статистическими методами анализа.
Так, они обеспечивают более точное и детальное исчисление влияния отдельных факторов на изменение величин экономических показателей а также дают возможность решения ряда аналитических задач, которые не могут быть сделаны без применения экономико-математических методов.
Факторный анализ является одним из наиболее мощных статистических средств анализа данных. В его основе лежит процедура объединения групп коррелирующих друг с другом переменных («корреляционных плеяд» или «корреляционных узлов») в несколько факторов.
Иными словами, цель факторного анализа - сконцентрировать исходную информацию, выражая большое число рассматриваемых признаков через меньшее число более емких внутренних характеристик, которые, однако, не поддаются непосредственному измерению (и в этом смысле являются латентными).
Для примера гипотетически представим себе законодательный орган регионального уровня, состоящий из 100 депутатов. В числе разных вопросов повестки дня на голосование выносятся: а) законопроект, предлагающий восстановить памятник В.И. Ленину на центральной площади города - административного центра региона; б) обращение к Президенту РФ с требованием вернуть в государственную собственность все стратегические производства. Матрица сопряженности показывает следующее распределение голосов депутатов:
Памятник Ленину (за) Памятник Ленину (против) Обращение к Президенту (за) 49 4 Обращение к Президенту (против) 6 41 Очевидно, что голосования статистически связаны: подавляющее большинство депутатов, поддерживающих идею восстановления памятника Ленину, поддерживают и возвращение в государственную собственность стратегических предприятий. Аналогичным образом большинство противников восстановления памятника являются в то же время и противниками возврата предприятий в госсобственность. При этом тематически голосования между собой совершенно не связаны.
Логично предположить, что выявленная статистическая связь обусловлена существованием некоторого скрытого (латентного) фактора. Законодатели, формулируя свою точку зрения по самым разнообразным вопросам, руководствуются ограниченным, небольшим набором политических позиций. В данном случае можно предположить наличие скрытого раскола депутатского корпуса по критерию поддержки/отвержения консервативно-социалистических ценностей. Выделяется группа «консерваторов» (согласно нашей таблице сопряженности - 49 депутатов) и их оппонентов (41 депутат). Выявив такие расколы, мы сможем описать большое число отдельных голосований через небольшое число факторов, которые являются латентными в том смысле, что мы не можем их обнаружить непосредственно: в нашем гипотетическом парламенте ни разу не проводилось голосование, в ходе которого депутатам предлагалось бы определить свое отношение к консервативно-социалистическим ценностям. Мы обнаруживаем наличие данного фактора, исходя из содержательного анализа количественных связей между переменными. Причем, если в нашем примере сознательно взяты номинальные переменные - поддержка законопроекта с категориями «за» (1) и «против» (0), - то в действительности факторный анализ эффективно обрабатывает интервальные данные.
Факторный анализ очень активно используется как в политической науке, так и в «соседних» социологии и психологии. Одна из важных причин большой востребованности данного метода состоит в разнообразии задач, которые можно решать с его помощью. Так, выделяются по крайней мере три «типовые» цели факторного анализа:
· уменьшение размерности (редукция) данных. Факторный анализ, выделяя узлы взаимосвязанных признаков и сводя их к неким обобщенным факторам, уменьшает исходный базис признаков описания. Решение этой задачи важно в ситуации, когда объекты измерены большим числом переменных и исследователь ищет способ сгруппировать их по смысловому признаку. Переход от множества переменных к нескольким факторам позволяет сделать описание более компактным, избавиться от малоинформативных и дублирующих переменных;
Выявление структуры объектов или признаков (классификация). Эта задача близка к той, которая решается методом кластер-анализа. Но если кластер-анализ принимает за «координаты» объектов их значения по нескольким переменным, то факторный анализ определяет положение объекта относительно факторов (связанных групп переменных). Иными словами, с помощью факторного анализа можно оценить сходство и различие объектов в пространстве их корреляционных связей, или в факторном пространстве. Координатными осями факторного пространства выступают полученные латентные переменные, на эти оси проецируются рассматриваемые объекты, что позволяет создать наглядное геометрическое представление изучаемых данных, удобное для содержательной интерпретации;
Косвенное измерение. Факторы, являясь латентными (эмпирически не наблюдаемыми), не поддаются непосредственному измерению. Однако факторный анализ позволяет не только выявить латентные переменные, но и оценить количественно их значение для каждого объекта.
Рассмотрим алгоритм и интерпретацию статистики факторного анализа на примере данных о результатах парламентских выборов в Рязанской области 1999 г. (общефедеральный округ). Для упрощения примера возьмем электоральную статистику только по тем партиям, которые преодолели 5%-ный барьер. Данные взяты в разрезе территориальных избирательных комиссий (по городам и районам области).
Первым шагом будет стандартизация данных путем перевода их в стандартные баллы (так называемые Л-баллы, рассчитываемые с помощью функции нормального распределения).
ТИК (территориальная избирательная комиссия)
«Яблоко» «Единство» Блок Жириновского
ОВР КПРФ СПС Ермишинская 1,49 35,19 6,12 5,35 31,41 2,80 Захаровская 2,74 18,33 7,41 11,41 31,59 л б 3 " Кадомская 1,09 29,61 8,36 5,53 35,87 1,94 Касимовская 1,30 39,56 5,92 5,28 29,96 2,37 Касимовская городская 3,28 39,41 5,65 6,14 24,66 4,61 То же в стандартизированных баллах (г-баллах) Ермишинская -0,83 1,58 -0,25 -0,91 -0,17 -0,74 Захаровская -0,22 -1,16 0,97 0,44 -0,14 0,43 Кадомская -1,03 0,67 1,88 -0,87 0,59 -1,10 Касимовская -0,93 2,29 -0,44 -0,92 -0,42 -0,92 Касимовская городская 0,04 2,26 -0,70 -0,73 -1,32 0,01 И т.д. (всего 32 случая) «Яблоко» «Единство» БЖ ОВР КПРФ СПС «Яблоко» «Единство» -0,55 БЖ -0,47 0,27 ОВР 0,60 -0,72 -0,47 КПРФ -0,61 0,01 0,10 -0,48 СПС 0,94 -0,45 -0,39 0,52 -0,67 Уже визуальный анализ матрицы парных корреляций позволяет сделать предположения о составе и характере корреляционных плеяд. К примеру, положительные корреляции обнаруживаются для «Союза правых сил», «Яблока» и блока «Отечество - вся Россия» (пары «Яблоко» - ОВР, «Яблоко» - СПС и ОВР - СПС). Одновременно эти три переменные отрицательно коррелируют с КПРФ (поддержка КПРФ), в меньшей степени - с «Единством» (поддержка «Единства») и в еще меньшей - с переменной БЖ (поддержка «Блока Жириновского»). Таким образом, предположительно мы имеем две выраженные корреляционные плеяды:
(«Яблоко» + ОВР + СПС) - КПРФ;
(«Яблоко» + ОВР + СПС) - «Единство».
Это две разные плеяды, а не одна, так как между «Единством» и КПРФ связи нет (0,01). Относительно переменной БЖ предположение сделать сложнее, здесь корреляционные связи менее выражены.
Чтобы проверить наши предположения, необходимо ВЫЧИСлить собственные значения факторов (eigenvalues), факторные значения (factor scores) и факторные нагрузки (factor loadings) для каждой переменной. Такие расчеты достаточно сложны, требуют серьезных навыков работы с матрицами, поэтому здесь мы не станем рассматривать вычислительный аспект. Скажем лишь, что эти вычисления могут осуществляться двумя путями: методом главных компонент (principal components) и методом главных факторов (principal factors). Метод главных компонент более распространен, статистические программы используют его «по умолчанию».
Остановимся на интерпретации собственных значений, факторных значений и факторных нагрузок.
Собственные значения факторов для нашего случая таковы:
Фактор Собственное значение % общей вариации 1 3,52 58,75 2 1,14 19,08 3 0,76 12,64 4 0,49 S.22 bgcolor=white>5 0,05 0.80 6 0,03 0,51 Всего 6 100% Чем больше собственное значение фактора, тем больше его объяснительная сила (максимальное значение равно количеству переменных, в нашем случае 6). Одним из ключевых элементов статистики факторного анализа является показатель «% общей вариации» (% total variance). Он показывает, какую долю вариации (изменчивости) переменных объясняет извлеченный фактор. В нашем случае вес первого фактора превосходит вес всех остальных факторов, вместе взятых: он объясняет почти 59% общей вариации. Второй фактор объясняет 19% вариации, третий - 12,6% и т.д. по убывающей.
Имея собственные значения факторов, мы можем приступить к решению задачи сокращения размерности данных. Редукция произойдет за счет исключения из модели факторов, обладающих наименьшей объяснительной силой. И здесь ключевой вопрос состоит в том, сколько факторов оставить в модели и какими критериями при этом руководствоваться. Так, явно лишними являются факторы 5 и 6, в совокупности объясняющие чуть более 1% всей вариации. А вот судьба факторов 3 и 4 уже не столь очевидна.
Как правило, в модели остаются факторы, собственное значение которых превышает единицу (критерий Кайзера). В нашем случае это факторы 1 и 2. Однако полезно проверить корректность удаления четырех факторов с помощью других критериев. Одним из наиболее широко используемых методов является анализ «графика осыпи» (scree plot). Для нашего случая он имеет вид:
График получил свое название из-за сходства со склоном горы. «Осыпь» - геологический термин, обозначающий обломки горных пород, скапливающиеся в нижней части скалистого склона. «Скала» - это по-настоящему влиятельные факторы, «осыпь» - статистический шум. Образно говоря, нужно найти место на графике, где кончается «скала» и начинается «осыпь» (где убывание собственных значений слева направо сильно замедляется). В нашем случае выбор нужно сделать из первого и второго перегибов, соответствующих двум и четырем факторам. Оставив четыре фактора, мы получим очень высокую точность модели (более 98% общей вариации), но сделаем ее достаточно сложной. Оставив два фактора, мы будем иметь значительную необъясненную часть вариации (около 22%), но модель станет лаконичной и удобной в анализе (в частности, визуальном). Таким образом, в данном случае лучше пожертвовать некоторой долей точности в пользу компактности, оставив первый и второй факторы.
Проверить адекватность полученной модели можно с помощью специальных матриц воспроизведенных корреляций (reproduced correlations) и остаточных коэффициентов (residual correlations). Матрица воспроизведенных корреляций содержит коэффициенты, которые удалось восстановить по двум оставленным в модели факторам. Особое значение в ней имеет главная диагональ, на которой расположены общности переменных (в таблице выделены курсивом), которые показывают, насколько точно модель воспроизводит корреляцию переменной с той же переменной, которая должна составлять единицу.
Матрица остаточных коэффициентов содержит разность между исходным и воспроизведенным коэффициентами. Например, воспроизведенная корреляция между переменными СПС и «Яблоко» составляет 0,88, исходная - 0,94. Остаток = 0,94 - 0,88 = 0,06. Чем ниже значения остатков, тем выше качество модели.
Воспроизведенные корреляции «Яблоко» «Единство» БЖ ОВР КПРФ СПС «Яблоко» 0,89 «Единство» -0,53 0,80 БЖ -0,47 0,59 0,44 ОВР 0,73 -0,72 -0,56 0,76 КПРФ -0,70 0,01 0,12 -0,34 0,89 СПС 0,88 -0,43 -0,40 0,66 -0,77 0,88 Остаточные коэффициенты «Яблоко» «Единство» БЖ ОВР КПРФ СПС «Яблоко» 0,11 «Единство» -0,02 0,20 БЖ 0,00 -0,31 0,56 ОВР -0,13 -0,01 0,09 0,24 КПРФ 0,09 0,00 -0,02 -0,14 0,11 СПС 0,06 -0,03 0,01 -0,14 0,10 0,12 Как видно из матриц, двухфакторная модель, будучи в целом адекватной, плохо объясняет отдельные связи. Так, очень низкой является общность переменной БЖ (всего 0,56), слишком велико значение остаточного коэффициента связи БЖ и «Единства» (-0,31).
Теперь необходимо решить, насколько важным для данного конкретного исследования является адекватное представление переменной БЖ. Если важность высока (к примеру, если исследование посвящено анализу электората именно этой партии), корректно вернуться к четырехфакторной модели. Если нет, можно оставить два фактора.
Принимая во внимание учебный характер наших задач, оставим более простую модели.Факторные нагрузки можно представить как коэффициенты корреляции каждой переменной с каждым из выявленных факторов 1ак, корреляция между значениями первой факторной переменной и значениями переменной «Яблоко» составляет -0,93. Все факторные нагрузки приводятся в матрице факторного отображения-
Чем теснее связь переменной с рассматриваемым фактором, тем выше значение факторной нагрузки. Положительный знак факторной нагрузки указывает на прямую, а отрицательный знак - на обратную связь переменной с фактором.
Имея значения факторных нагрузок, мы можем построить геометрическое представление результатов факторного анализа. По оси X отложим нагрузки переменных на фактор 1, по оси Y- нагрузки переменных на фактор 2 и получим двухмерное факторное пространство.

Перед тем как приступить к содержательному анализу полученных результатов, осуществим еще одну операцию - вращение (rotation). Важность этой операции продиктована тем, что существует не один, а множество вариантов матрицы факторных нагрузок, в равной степени объясняющих связи переменных (матрицу интеркорреляций). Необходимо выбрать такое решение, которое проще интерпретировать содержательно. Таковым считается матрица нагрузок, в которой значения каждой переменной по каждому фактору максимизированы или минимизированы (приближены к единице или к нулю).
Рассмотрим схематичный пример. Имеется четыре объекта, расположенных в факторном пространстве следующим образом:

Нагрузки на оба фактора для всех объектов существенно отличны от нуля, и мы вынуждены привлекать оба фактора для интерпретации положения объектов. Но если «повернуть» всю конструкцию по часовой стрелке вокруг пересечения осей координат, получим следующую картинку:
В данном случае нагрузки на фактор 1 будут близки к нулю, а нагрузки на фактор 2 - к единице (принцип простой структуры). Соответственно, для содержательной интерпретации положения объектов мы будем привлекать только один фактор - фактор 2.
Существует довольно большое количество методов вращения факторов. Так, группа методов ортогонального вращения всегда сохраняет прямой угол между координатными осями. К таковым относятся vanmax (минимизирует количество переменных с высокой факторной нагрузкой), quartimax (минимизирует количество факторов, необходимых для объяснения переменной), equamax (сочетание двух предыдущих методов). Методы косоугольного вращения не обязательно сохраняют прямой угол между осями (например, direct obiimin). Метод promax представляет собой сочетание ортогонального и косоугольного методов вращения. В большинстве случаев используется метод vanmax, который дает хорошие результаты применительно и к большинству задач политических исследований. Кроме того, как и в процессе применения многих других методов, рекомендуется поэкспериментировать с различными техниками вращения.
В нашем примере после вращения методом varimax получаем следующую матрицу факторных нагрузок:
Соответственно, геометрическое представление факторного пространства будет иметь вид:

Теперь можно приступить к содержательной интерпретации полученных результатов. Ключевую оппозицию - электоральный раскол - по первому фактору формируют КПРФ с одной стороны и «Яблоко» и СПС (в меньшей степени ОВР) - с другой. Содержательно - исходя из специфики идеологических установок названных субъектов избирательного процесса - мы можем интерпретировать данное размежевание как «лево-правый» раскол, являющийся «классическим» для политической науки.
Оппозицию по фактору 2 формируют ОВР и «Единство». К последнему примыкает «Блок Жириновского», но достоверно судить о его положении в факторном пространстве мы не можем в силу особенностей модели, которая плохо объясняет связи именно этой переменной. Чтобы объяснить такую конфигурацию, необходимо вспомнить политические реалии избирательной кампании 1999 г. Тогда борьба внутри политической элиты привела к формированию двух эшелонов «партии власти» - блоков «Единство» и «Отечество - вся Россия». Различие между ними не носило идеологического характера: фактически населению предложили выбирать не из двух идейных платформ, а из двух элитных групп, каждая из которых располагала существенными властными ресурсами и региональной поддержкой. Таким образом, этот раскол можно интерпретировать как «властно-элитный» (или, несколько упрощая, «власть - оппозиция»).
В целом мы получаем геометрическое представление некоего электорального пространства Рязанской области для данных выборов, если понимать электоральное пространство как пространство электорального выбора, структуру ключевых политических альтернатив («расколов»). Комбинация именно этих двух расколов была очень типична для парламентских выборов 1999 г.
Сопоставляя результаты факторного анализа для одного и того же региона на разных выборах, мы можем судить о наличии преемственности в конфигурации пространства электорального выбора территории. К примеру, факторный анализ федеральных парламентских выборов (1995, 1999 и 2003 гг.), проходивших в Татарстане, показал устойчивую конфигурацию электорального пространства. Для выборов 1999 г. в модели оставлен всего один фактор с объяснительной силой 83% вариации, что сделало невозможным построение двухмерной диаграммы. В соответствующем столбце приведены факторные нагрузки.
Если внимательно присмотреться к этим результатам, можно заметить, что в республике от выборов к выборам воспроизводится один и тот же основной раскол: «"партия власти” - все остальные». «Партией власти» в 1995 г. выступал блок «Наш дом - Россия» (НДР), в 1999 г. - ОВР, в 2003 г. - «Единая Россия». С течением времени меняются лишь «детали» - название «партии власти». Новый политический «лейбл» очень легко ложится в статичную матрицу одномерного политического выбора.
В заключение главы дадим один практический совет. Успешность освоения статистических методов по большому счету возможна только при интенсивной практической работе со специальными программами (уже неоднократно упомянутые SPSS, Statistica или хотя бы Microsoft Excel). Не случайно изложение статистических техник ведется нами в режиме алгоритмов работы: это позволяет студенту самостоятельно пройти все стадии анализа, сидя за компьютером. Без попыток практического анализа реальных данных представление о возможностях статистических методов в политическом анализе неизбежно останется общим и абстрактным. А на сегодняшний день умение применять статистику для решения и теоретических, и прикладных задач - принципиально важная составляющая модели специалиста-политолога.
Контрольные вопросы и задания
1. Каким уровням измерения соответствуют средние величины - мода, медиана, среднее арифметическое? Какие меры вариации характерны для каждой из них?
2. В силу каких причин необходимо учитывать форму распределения переменных?
3. Что означает утверждение: «Между двумя переменными имеется статистическая связь»?
4. Какую полезную информацию о связях между переменными можно получить на основе анализа таблиц сопряженности?
5. Что можно узнать о связи между переменными, исходя из значений статистических критериев хи-квадрат и лямбда?
6. Дайте определение понятию «ошибка» в статистических исследованиях. Каким образом по данному показателю можно судить о качестве построенной статистической модели?
7. Какова основная цель корреляционного анализа? Какие характеристики статистической связи выявляет данный метод?
8. Как интерпретировать значение коэффициента корреляции Пирсона?
9. Охарактеризуйте метод дисперсионного анализа. В каких других статистических методах используется статистика дисперсионного анализа и для чего?
10. Объясните значение понятия «нулевая гипотеза».
11. Что такое линия регрессии, каким методом она строится?
12. Что показывает коэффициент R в итоговой статистике регрессионного анализа?
13. Поясните термин «метод многомерной классификации».
14. Объясните основные различия между кластеризацией посредством иерархического кластер-анализа и методом К-средних.
15. Каким образом кластер-анализ может использоваться при изучении имиджа политических лидеров?
16. Какова основная задача, решаемая посредством дискриминантного анализа? Дайте определение дискриминантной функции.
17. Назовите три класса задач, решаемых с помощью факторного анализа. Конкретизируйте понятие «фактор».
18. Дайте характеристику трем основным методам проверки качества модели в факторном анализе (критерий Кайзера, критерий «осыпи», матрица воспроизведенных корреляций).
- Міжнародна міграція фінансових ресурсів у контексті факторного аналізу
- 25. Ж.-Б. Сэй вошел в историю экономической науки как автор факторной теории стоимости. Каковы основные положения этой теории?
- Технико-экономический анализ строительного проекта и анализ обеспечения по запрашиваемому строительному кредиту
- определение взаимосвязей между переменными, их классификация, т. е. «объективная R-классификация»;
- сокращение числа переменных.
- Все признаки должны быть количественными;
- Число признаков должно быть в два раза больше числа переменных;
- Выборка должна быть однородна;
- Исходные переменные должны быть распределены симметрично;
- Факторный анализ осуществляется по коррелирующим переменным.
Все явления и процессы хозяйственной деятельности предприятий находятся во взаимосвязи и взаимообусловленности. Одни из них непосредственно связаны между собой, другие косвенно. Отсюда важным методологическим вопросом в экономическом анализе является изучение и измерение влияния факторов на величину исследуемых экономических показателей.
Факторный анализ в учебной литературе трактуется как раздел многомерного статистического анализа, объединяющий методы оценки размерности множества наблюдаемых переменных посредством исследования структуры ковариационных или корреляционных матриц.
Свою историю факторный анализ начинает в психометрике и в настоящее время широко используется не только в психологии, но и в нейрофизиологии, социологии, политологии, в экономике, статистике и других науках. Основные идеи факторного анализа были заложены английским психологом и антропологом Ф. Гальтоном . Разработкой и внедрением факторного анализа в психологии занимались такие ученые как: Ч.Спирмен, Л.Терстоун и Р.Кеттел . Математический факторный анализ разрабатывался Хотеллингом, Харманом, Кайзером, Терстоуном, Такером и другими учеными.
Данный вид анализа позволяет исследователю решить две основные задачи: описать предмет измерения компактно и в то же время всесторонне. С помощью факторного анализа возможно выявление факторов, отвечающих за наличие линейных статистических связей корреляций между наблюдаемыми переменными.
Цели факторного анализа
К примеру, анализируя оценки, полученные по нескольким шкалам, исследователь отмечает, что они сходны между собой и имеют высокий коэффициент корреляции, в этом случае он может предположить, что существует некоторая латентная переменная , с помощью которой можно объяснить наблюдаемое сходство полученных оценок. Такую латентную переменную называют фактором, который влияет на многочисленные показатели других переменных, что приводит к возможности и необходимости отметить его как наиболее общий, более высокого порядка.
Таким образом, можно выделить две цели факторного анализа :
Для выявления наиболее значимых факторов и, как следствие, факторной структуры, наиболее оправданно применять метод главных компонентов . Суть данного метода состоит в замене коррелированных компонентов некоррелированными факторами. Другой важной характеристикой метода является возможность ограничиться наиболее информативными главными компонентами и исключить остальные из анализа, что упрощает интерпретацию результатов. Достоинство данного метода также в том, что он - единственный математически обоснованный метод факторного анализа.
Факторный анализ - методика комплексного и системного изучения и измерения воздействия факторов на величину результативного показателя.
Типы факторного анализа
Существуют следующие типы факторного анализа:
1) Детерминированный (функциональный) - результативный показатель представлен в виде произведения, частного или алгебраической суммы факторов.
2) Стохастический (корреляционный) - связь между результативным и факторными показателями является неполной или вероятностной.
3) Прямой (дедуктивный) - от общего к частному.
4) Обратный (индуктивный) - от частного к общему.
5) Одноступенчатый и многоступенчатый.
6) Статический и динамический.
7) Ретроспективный и перспективный.
Также факторный анализ может быть разведочным - он осуществляется при исследовании скрытой факторной структуры без предположения о числе факторов и их нагрузках и конфирматорным , предназначенным для проверки гипотез о числе факторов и их нагрузках. Практическое выполнение факторного анализа начинается с проверки его условий.
Обязательные условия факторного анализа:
При анализе в один фактор объединяются сильно коррелирующие между собой переменные, как следствие происходит перераспределение дисперсии между компонентами и получается максимально простая и наглядная структура факторов. После объединения коррелированность компонент внутри каждого фактора между собой будет выше, чем их коррелированность с компонентами из других факторов. Эта процедура также позволяет выделить латентные переменные, что бывает особенно важно при анализе социальных представлений и ценностей.
Этапы факторного анализа
Как правило, факторный анализ проводится в несколько этапов.
Этапы факторного анализа:
1 этап. Отбор факторов.
2 этап. Классификация и систематизация факторов.
3 этап. Моделирование взаимосвязей между результативным и факторными показателями.
4 этап. Расчет влияния факторов и оценка роли каждого из них в изменении величины результативного показателя.
5 этап. Практическое использование факторной модели (подсчет резервов прироста результативного показателя).
По характеру взаимосвязи между показателями различают методы детерминированного и стохастического факторного анализа
Детерминированный факторный анализ представляет собой методику исследования влияния факторов, связь которых с результативным показателем носит функциональный характер, т. е. когда результативный показатель факторной модели представлен в виде произведения, частного или алгебраической суммы факторов.
Методы детерминированного факторного анализа : Метод цепных подстановок; Метод абсолютных разниц; Метод относительных разниц; Интегральный метод; Метод логарифмирования.
Данный вид факторного анализа наиболее распространен, поскольку, будучи достаточно простым в применении (по сравнению со стохастическим анализом), позволяет осознать логику действия основных факторов развития предприятия, количественно оценить их влияние, понять, какие факторы, и в какой пропорции возможно и целесообразно изменить для повышения эффективности производства.
Стохастический анализ представляет собой методику исследования факторов, связь которых с результативным показателем в отличие от функциональной является неполной, вероятностной (корреляционной). Если при функциональной (полной) зависимости с изменением аргумента всегда происходит соответствующее изменение функции, то при корреляционной связи изменение аргумента может дать несколько значений прироста функции в зависимости от сочетания других факторов, определяющих данный показатель.
Методы стохастического факторного анализа : Способ парной корреляции; Множественный корреляционный анализ; Матричные модели; Математическое программирование; Метод исследования операций; Теория игр.
Необходимо также различать статический и динамический факторный анализ. Первый вид применяется при изучении влияния факторов на результативные показатели на соответствующую дату. Другой вид представляет собой методику исследования причинно-следственных связей в динамике.
И, наконец, факторный анализ может быть ретроспективным, который изучает причины прироста результативных показателей за прошлые периоды, и перспективным, который исследует поведение факторов и результативных показателей в перспективе.